2-1. Gitを用いたプログラムの共同開発
演習2-1
Eclipse で以下を実施する
- File→import
- Projects from GITを選び next
- clone URI を選び next
- url には git://edu.net.c.dendai.ac.jp/git/spro/2/1 を入 力し next
- next
- Local Directry では、ドキュメントフォルダなど、整理の良 いフォルダを指定し next
- import existing Eclipse projects を選びnext
- spro2というプロジェクトができることを確認して finish
付録に示したプログラムが読み込まれる
- プロジェクト名を右クリックして Team→Show in History を選び、ブランチ名 master, リモートブランチ名 origin/master 現在の リポジトリ HEAD が一致していることを確認する。
-
クラス A999.java をコピーして、 A(学籍番号).java を作る。 名前と学籍番号を変更する。文字化けしている場合は Property で Text file encoding を UTF-8 などに変更する。
package spro2; public class A200 extends AbstractA { @Override public String name() { return "坂本直志200"; } @Override public String id() { return "99ec200"; } } -
Main.java において、配列中に new A999(), と同様に新しく作成し たクラスインスタンスを入れるように修正する。 正常に動作するかどうか、実際にプログラムを実行して確かめる。
package spro2; import java.util.Arrays; public class Main { public static void main(String[] args) { A[] list = { new A999(), new A200(), }; Arrays.stream(list) .forEach(System.out::println); } } -
Add Index, Commitを行う
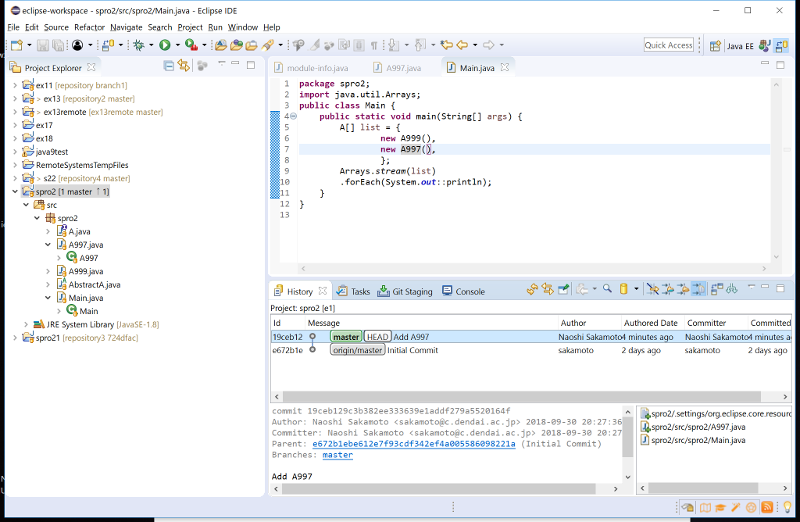
- Team → Remote → Configure fetch from Upstream で url を git://edu.net.c.dendai.ac.jp/git/spro/2/2 に変更し、 save
-
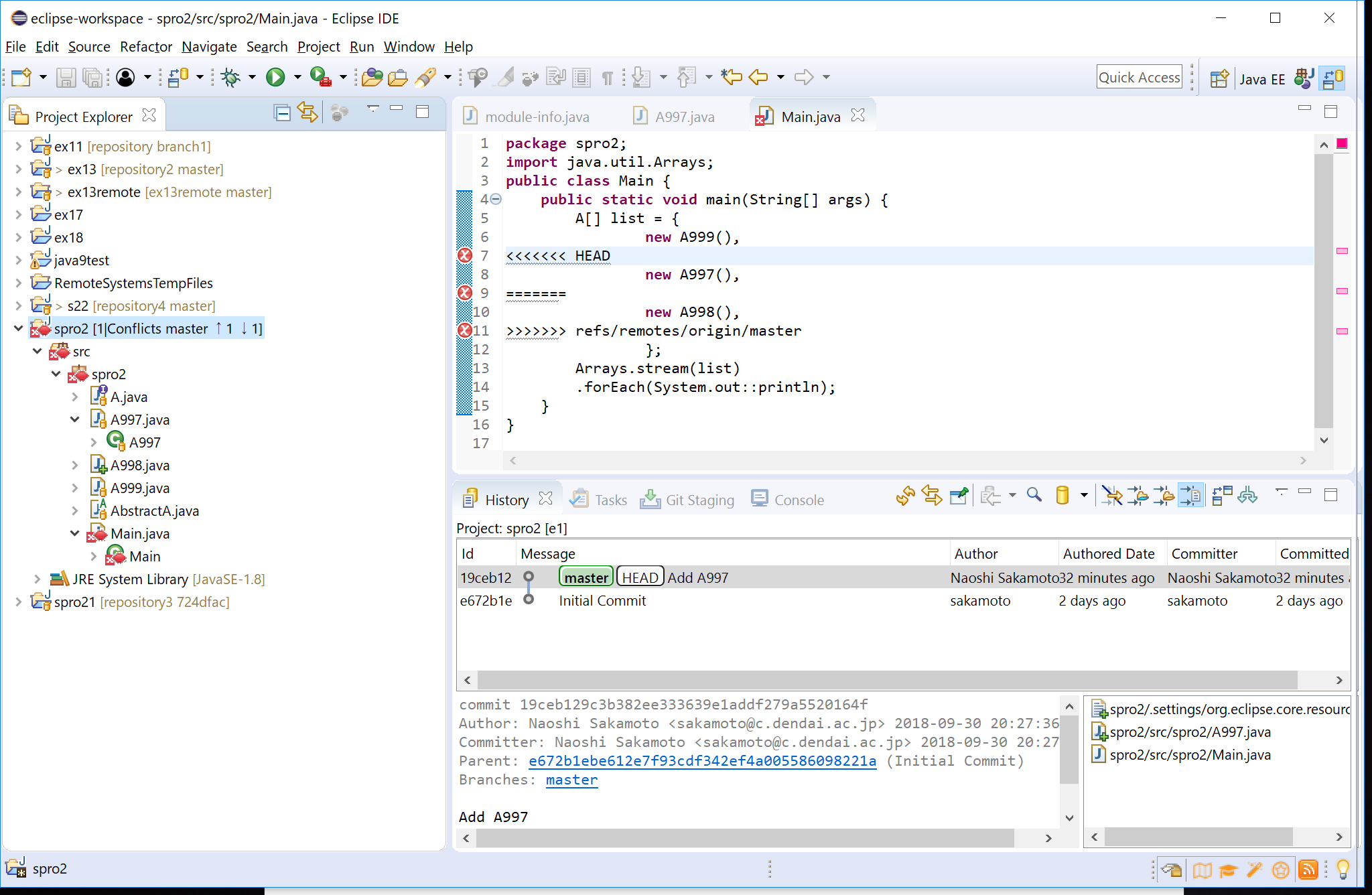
Team → pull をするとサーバ側の変更が読み込まれる(pull は fetch + merge なので、直前で save ではなく save and fetch を選んだ場合は、 pull の代わりに merge する)。 矛盾がなければ単なる変更と同様になるが、矛盾が生じるとファイル に赤丸が付加され、報告される
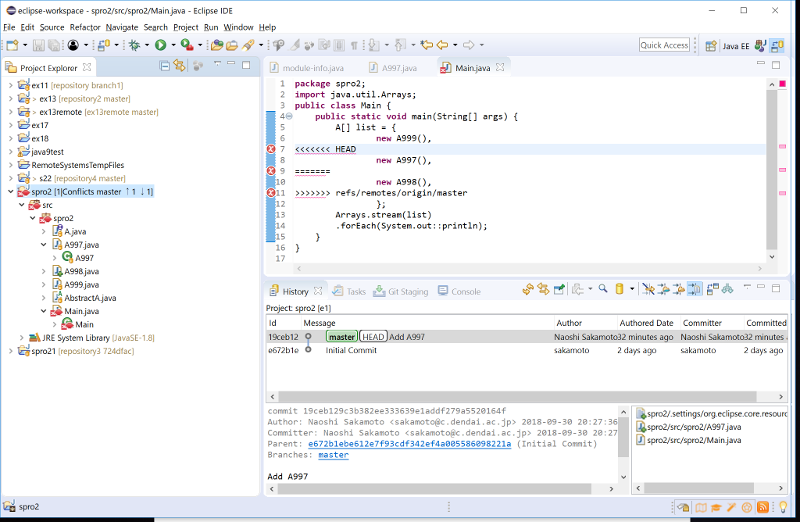
- show in histry で origin/master が消えている
- Problems では矛盾点がファイルごとにメッセージされる
-
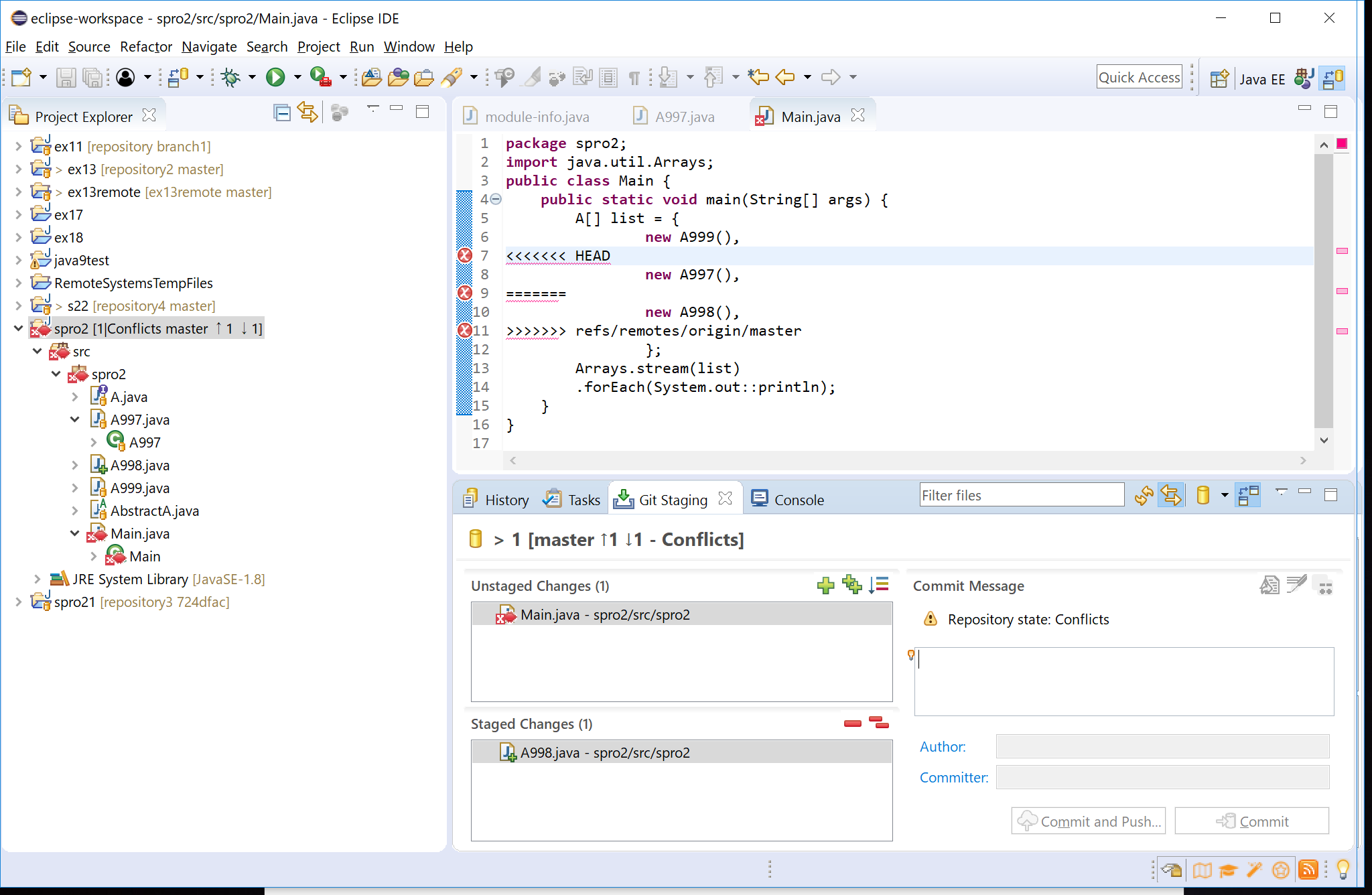
Git Staging では、問題あるファイルが赤丸で表され Unstaged にリストされる。 問題なかった追加部分は Staged にリストされる
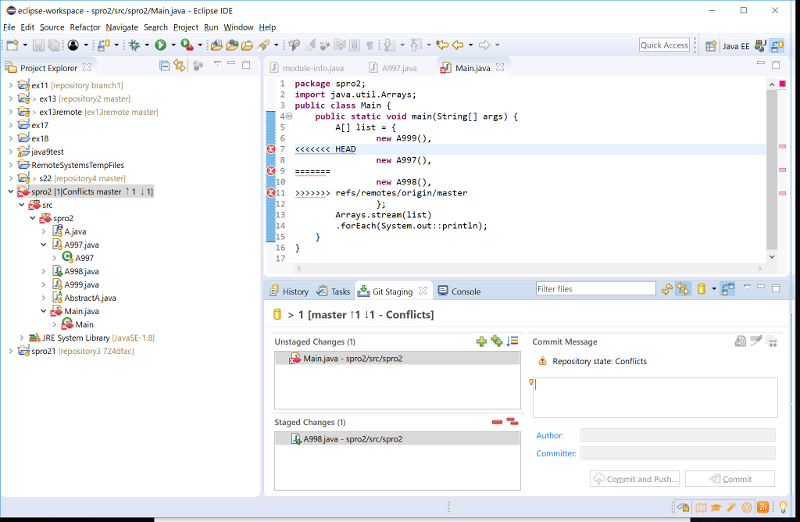
-
package spro2; import java.util.Arrays; public class Main { public static void main(String[] args) { A[] list = { new A999(), <<<<<<< HEAD new A200(), ======= new A998(), >>>>>>> branch 'master' of git://edu.net.c.dendai.ac.jp/git/spro/2/2 }; Arrays.stream(list) .forEach(System.out::println); } }これをファイルを修正して、実行できるようにする。
package spro2; import java.util.Arrays; public class Main { public static void main(String[] args) { A[] list = { new A999(), new A200(), new A998(), }; Arrays.stream(list) .forEach(System.out::println); } } - 正常に修正できたことを確認して、 add index を行い、 staging す る
-
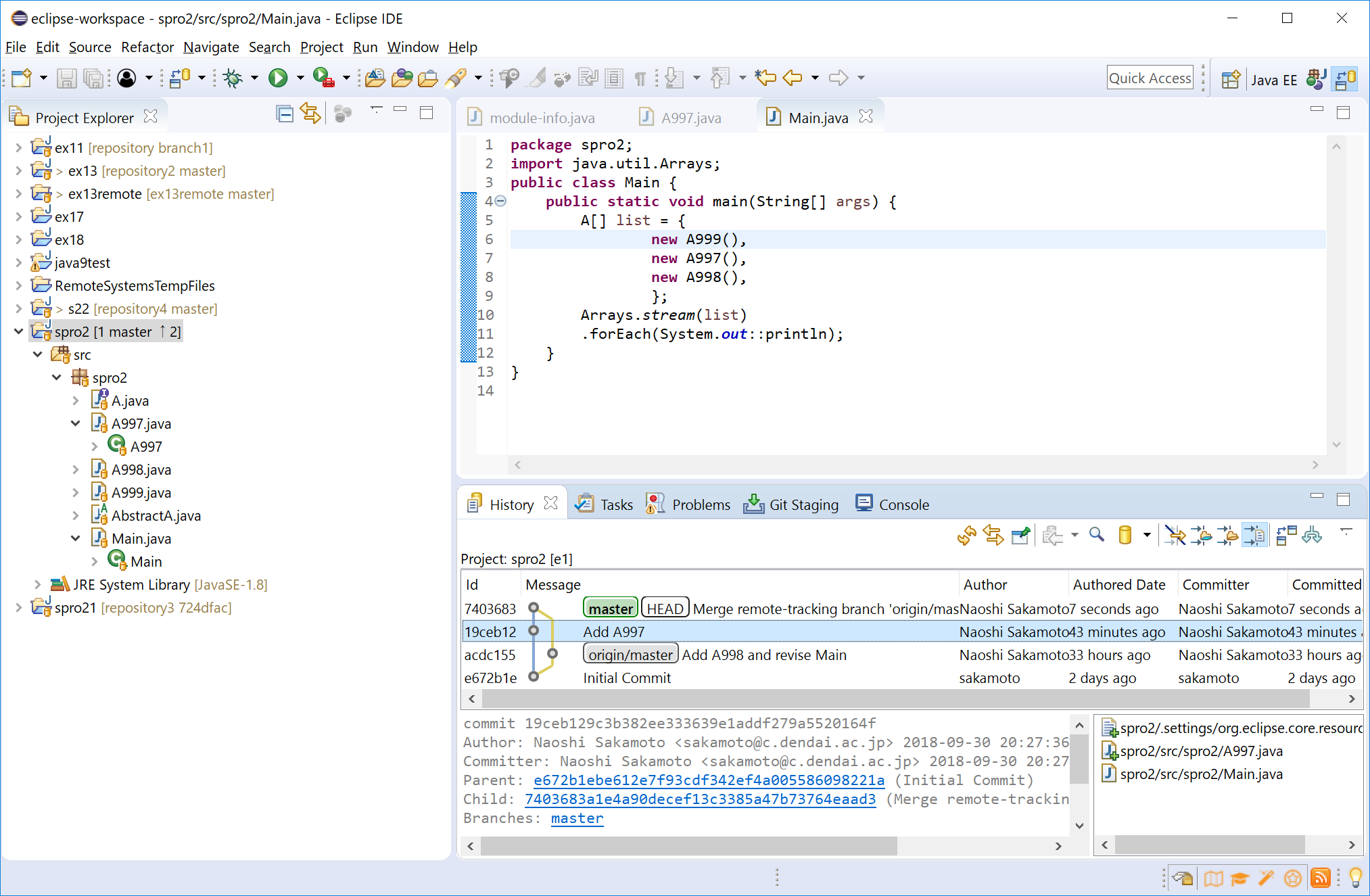
すべての赤丸のファイルを修正し、 staging したら、 commmit する。
-
History で、外部修正と内部修正が合流したことがわか る
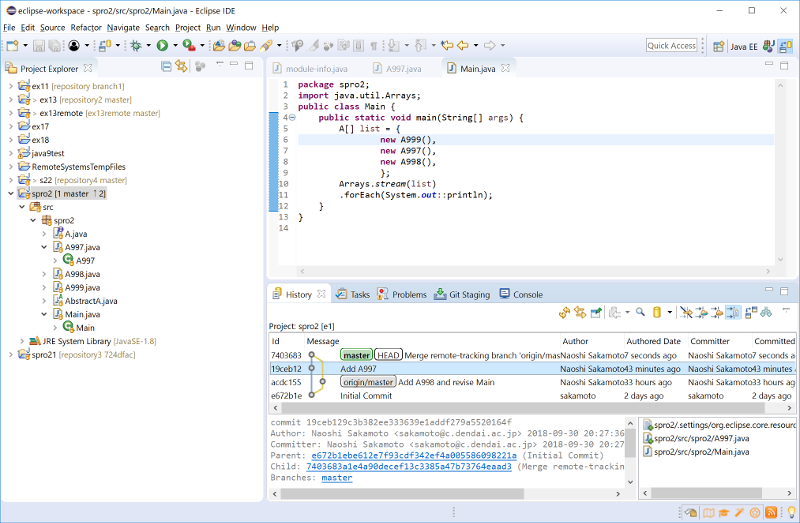
- Problemsが解決している
-
演習2-2
USB メモリーにリモートリポジトリを作り、着席している周囲でプログ ラムを共有しなさい。
-
代表で一人が USBメモリーにリポートリポジトリを作成する
- USBメモリーのドライブ名を d: と仮定する
- git bash を起動する
mkdir /d/git mkdir /d/git/spro mkdir /d/git/spro/2 git init --bare --share /d/git/spro/2
- 演習2-1 において、Eclipse の Team→remote→configure fetch for remote の手順で授業 用のサーバーの代わりに file:///d:/git/spro/2 を指定する
- 演習2-1の操作がすべて終わった段階で Team→push to Upstream を行う。
演習2-3
作成したプログラムを、学籍番号順に表示するように改良したい。
-
リストを sort で並べ替えてから表示するようにする。
Arrays.stream(list) .sorted() .forEach(System.out::println); -
package spro2; public interface A extends Comparable<A> { String name(); String id(); }オブジェクトが並び替えられる条件は Java では java.lang.Comparable を実装していることである。
そのため、インターフェイス A に Comparable を継承させる
-
比較を実施するプログラムをすべてのクラスの共通部分である AbstractA クラスに実装する。 実装しなければならないメソッドは以下の 3 つである。
- bool equals(Object o)
- int hashCode()
- int compareTo(A a)
- これらのメソッドの雛形を得るために、ダミーで AbstractA の中にフィー ルド Strng a; を仮に作る
- compareTo の雛形を作るには、 Comparable のメソッドなので Source→Override/inherit Methods を選び、 compareTo のみをチェックして Ok を押します
- Source → Generate hashCode() and equals() を選び Ok を押す
- ここでセーブするとエラーがすべて消えることを確認する。
- ここで一回 commit しておく
演習2-4
次回、次次回の導入
テスト環境を作ります。
- src フォルダを右クリックして new → package で test パッケージ を作る。
- A.java を右クリックして new→Other→Java→JUnit→JUnit Test Case を選び next
- Package を test にし、 setUp をチェックして next
- テストを作るメソッドとして compareTo をチェックして Finish する
-
以下のプログラムを入れる
package test; import static org.junit.jupiter.api.Assertions.*; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import spro2.A; import spro2.A998; import spro2.A999; class ATest { private A999 a999; private A998 a998; @BeforeEach void setUp() throws Exception { a999 = new A999(); a998 = new A998(); } @Test void testCompareTo() { assertTrue(a998.compareTo(a999)<0); assertTrue(a998.compareTo(a998)==0); assertTrue(a999.compareTo(a999)==0); assertTrue(a999.compareTo(a998)>0); } @Test void testEquals() { assertFalse(a998.equals(null)); assertFalse(a998.equals("99ec999")); assertTrue(a998.equals(a998)); assertFalse(a998.equals(a999)); } private boolean hashCodeCondition(A a1, A a2) { return !a1.equals(a2)||(a1.hashCode()==a2.hashCode()); } @Test void testHashCode() { assertTrue(hashCodeCondition(a998,a998)); assertTrue(hashCodeCondition(a998,a999)); assertTrue(hashCodeCondition(a999,a998)); assertTrue(hashCodeCondition(a999,a999)); } } - ここで一旦コミットする
2-2. 比較
次にオブジェクトの比較について考えます。 同一メモリアドレス上にある、つまり、まさに参照先が同じかどうかを判定するには == を使用します。
しかし、文字列など、異なるメモリ上にあっても 内容が等しければ等しいと判断したいときがあります。 そのため java.lang.Object には equals というメソッドがあります。 このメソッドを各オブジェクトクラスの性質に応じてオーバライドして使用します。 equals を実装する際もコピーと同様に浅く比較するか、深く比較するかを検 討する必要があります。 なお、配列では java.util.Arrays に静的なメソッドとして equals と deepEquals が実装されています。
equals
equals は数学でいう同値関係を満たす必要があります。つまり次 の三条件を満たさなければなりません。
null でない Object a,b,c に対しては、次を満たします。
- 反射律
a.equals(a)は true- 対称律
a.equals(b)とb.equals(a)は一致する- 推移律
-
a.equals(b)とb.equals(c)がともに true で あるなら、a.equals(c)も true
この上、プログラミング的な制約として、オブジェクトが変化しない限りは何
度 equal を呼んでも結果が変化しないという整合性(初回だけ true で 2 回
目以降は false というのはダメ)と、 x.equals(null) は常に
false でなければならないという条件が付加されてます。
以上挙げた条件を実際に満たすことはそれほど厳しいことではないので、 いろいろな条件の equals を考えることができます。 例えば、「ある条件が成立する同一グループ」は大抵この性質を持っています。 つまり、例えば数を比較する場合、「値が完全に等しい」という条件の他に、 「3 で割った余りが等しい整数」なども上記の条件を満たします。 但し、 equals の字面は「等しい」を意味しますので、等しさからあまり直感 的に外れた定義をすると、プログラムが作りにくくなったり読みづらくなった りしますので、注意が必要です。
例2-1
オンラインショッピングなどで顧客データを扱う際、通常顧客の ID で全て識 別します。 そのため、 equals の実装としてふさわしいのは次のように顧客の ID の比較 になります。
class Customer {
private String id;
...
/**
* 顧客の等価性を返します
* @param 顧客オブジェクト
* @return 同一の顧客かどうか
*/
public boolean equals(Customer customer){
return this.id.equals(customer.id);
}
}
なお、java.lang.Object における equals の引数は java.lang.Object なの で、この equals は Override にはなりません。 厳密に java.lang.Object の equals 関数を Override するためには、引数を Object 型にしなければなりません。 引数を Object に許すと、引数に対してそのまま Customer のメソッドを適用 できなくなります。つまり、キャストする必要があります。
/*
問題あり
*/
class Customer {
private String id;
...
@Override
public boolean equals(Object o){
Customer customer = (Customer) o;
return this.id.equals(customer.id);
}
}
ただし、このままでは equals の引数に null が与えられた場合や Customer クラスとは異なるオブジェクトが与えられた時に false が返りません。 さて、 Eclipse にはこの equals を自動生成する機能があります。 Customer に関して Eclipse に生成させると、次のようなプログラムを生成し ます。
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
final Customer other = (Customer) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
return true;
}
このようにかなり複雑な条件式になります。 このうち、最初の条件は単なる高速化のためですが、それ以降は、引数 obj とインスタンス変数 id に関して次のような条件を考えています。
- obj == null
- false
- obj が Customer 以外のオブジェクト
- false
- ここでやっと obj をキャストしてもエラーにならない。
- id == null
- なんと obj.id == null を返す。つまり両方共 null なら true、一方だ けが null なら false
- id が null でないことが分かる
- ここで、やっと id.equals(obj.id) が返せる
なお、 getClass を用いる代わりに
instanceof 演算子を使うと、
null のチェックとクラスのチェックが同時にできます。
これを用いて Eclipse の記述をより短くすると次のようになります。
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Customer)) return false;
final Customer other = (Customer) obj;
if (id == null) return other.id==null;
return id.equals(other.id);
}
最初の if 文以外はガード文になっていて、そこで return しないと、次のス テップで必ずランタイムエラーが出ることに注意してください。 つまり、obj が Customer クラスのインスタンスで無い限りキャストできませ んし、id が null では equals メソッドを呼べないということです。
hashCode
さて、等しいという条件として別の条件を考えてみましょう。 例えば、顧客 ID は異なっていても、名前と誕生日とお届先が一致して いるような顧客は本当に異なっているのでしょうか? コンピュータは条件さえそろえられれば、大量の顧客リストに関して、同一人 物の可能性のあるような顧客 ID リストなどを簡単に作ることができます。 誕生日自体は個人を特定しませんが、「異なっていれば別人」という情報を持っ ています。 電子マネーの ID や、レシート番号など、直接は個人情報にあたらないもので も大量に入手して処理することで個人を特定できることがあります。 このような情報処理を紐付けと呼びます。 個人情報保護が立法化され、社会的に個人情報の取扱いに注意が払われるよう になりました。 一方で、コンピュータの情報処理により、単独で は無意味な情報が個人の特定に大きく関与するようになりました。 そのため、法的には個人情報に当たらない情報でも、複数そろうと個人を特定で きてしまうこともあります。 そのため、 データベースなどを作る際には、情報を取り扱う責任や障害時の被害の軽減な ども考え、「責任の明確化」や「不必要な情報を採取しない」などの対応を考 える必要があります。
さて、話がそれました。
再び、「等しさ」の話に戻します。
java.lang.Object の equals の説明には
hashCode の実装をするように書かれています。
この hashCode(ハッシュ値) というのは各オブジェクトから作成
する長さの決まった値です。
Java では int 型、つまり 32bit になります。
このハッシュ値は equals の性質を一部受け継いでいます。
つまり、Object a,b に対して、 a.equals(b) が true である
なら、 a.hashCode() == b.hashCode() も成り立たなければな
らないということです。
これは a.equals(b) が false である場合には、何も規定して
ません。
対偶を考えると、a.hashCode() と b.hashCode()
が異なる場合は必ず a.equals(b) は false になるということ
です。
これは先ほどお話した誕生日がもつ条件と同じです。
「同一人物であれば誕生日が等しい」ということは、「誕生日が異なれば同一
人物では無い」ということです。
このようにハッシュ値というのはオブジェクトを表す一部の情報になります。
そして、equals は自由に設定できるという説明をしましたが、その場合、そ
の equals に連動したハッシュ値、つまり equals が true になるようなオブ
ジェクトに対しては常にハッシュ値が等しくなるようにする必要があります。
例2-2
例2-1 では顧客の等価条件を顧客の ID と定めましたので、 hashCode は顧客 ID のハッシュ値を返すようにします。
class Customer {
private String id;
...
/**
* 顧客の等価性を返します
* @param 顧客オブジェクト
* @return 同一の顧客かどうか
*/
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Customer)) return false;
final Customer other = (Customer) obj;
if (id == null) return other.id==null;
return id.equals(other.id);
}
/**
* 顧客のハッシュ値を返します。
* これは顧客ID のハッシュ値と等しいです。
* @return ハッシュ値
*/
@Override public int hashCode(){
return id.hashCode();
}
}
なお、例えば、名前と生年月日が等しい時に equals が true を返すという場 合、どのように hashCode を返せば良いでしょうか? 複数のデータを持つオブジェクトの代表格として文字列型 java.lang.String があります。 このオブジェクトの hashCode はマニュアルによると次のように計算されます。
このように、複数のデータに対してハッシュコードを計算するには、 直前の値 x とデータ値 y に対して 31*x + y という値を与えています。
そのほかの与え方として、 java.lang.Long (64 bit の整数)では、上位 32 bit と下位 32 bit の排他的論理和を取っています。 排他的論理和は一方が 1 bit 異なれば、値になります。しかし、二つの同じ 値に対して排他的論理和をとると 0 になってしまうという性質もあります。 64bit の整数に対して、上位と下位が一致してしまうというのはあまり考えら れない状況ですが、文字列に関しては 1 文字目と 2 文字目が一致することは 十分考えられます。 したがって、複数のオブジェクトのハッシュコードの算出方法は少なくとも次 の二通りが使われています。
| オブジェクトの性質 | 演算 | 代表的な例 |
|---|---|---|
| 二つが一致する可能性が低い | 排他的論理和 x^y | java.lang.Long, java.lang.Double |
| その他 | 31*x + y | java.lang.String など |
異なる要素に対してなるべく異なる hashCode を用意すると、hashCode を使 うようなアプリケーションで検索などが高速になります。
なお、 Eclipse ではこのようなルールに基づいて equals と hashCode を自 動的に生成します。
補足
なぜ 31 という特定の値を使うのかですが、 ひとつは 2 の 5 乗 - 1 という計算のしやすい値であることです。 もうひとつは以下の通りです。
まず、 31 の代わりに変数 x を用いて 二つの文字列 s[0,...,n-1] と t[0,...,n-1] に関して hashCode を求めると 次のようになります。
但し、これは高々 32 bit の演算なので、 で割った余りを考えることになります。 これが 一致する可能性を考えます。そこで、これに対して辺々引くと次のようになります。
hashCode がなるべく重ならないようにするには、 この多項式に対して、多項式の値が 0 になる個数が少ない x を求めることに なります。 まず、 x = 0 や などの場合、全ての多項式が 0 になります。 また、 x が の約数である場合、各項で積が となるような係数は 0 と 以外にいくつか存在することになるので、 0 になる個数が増えます。 したがって、まず最初の条件として、 x は と互いに素でなければなりません。
次に多項式の各項について、 x を何乗すると元に戻るかを考えます。 オイラー関数 には次の性質があります。
ここで、 は必ず n で割れば 1 余りますが、 だからと言って、 とは言えません。
ここで、 n が合成数の場合は、 で始めて mod n で 1 となるような要素 x は必ずしも 存在しません (素数なら必ず存在します)。
ここで値を代入します。 なので、 つまり、 31 が十分大きな k まで全て を満たしているかどうかを検証すべきです。 しかし、実際は慣習で使われています。 なお、従来は 37 や 17 などが使われていました。
順序
次に、顧客を顧客 ID 順や名前順などに並べる方法を考えましょう。 例で示した顧客のオブジェクトは hashCode が与えられてはいますが、順番に 並べる条件は何も示していません。 このままでは順番に並びません。 そこで順番をあたえます。 Java では順番を与えるには java.lang.Comparable インターフェイスを implement し、 compareTo メソッドを実装します。
package java.lang;
public interface Comparable<T>{
int compareTo(T o);
}
オブジェクト a, b に対して、 compareTo メソッドは次のような値を返すよ うに実装します。
- a<b
- a.compareTo(b)<0
- a==b
- a.compareTo(b)==0
- a>b
- a.compareTo(b)>0
数学では順序と比較は似たような概念になっています。この compareTo に関 して、これが全順序関係になるには次の条件を満たす必要があり ます。
- 反射律
a.compareTo(a)は 0- 反対称律
- 任意の要素に対して
a.compareTo(b)と-b.compareTo(a)の符号は等しい(あるいはともに 0) - 推移律
-
a.compareTo(b)とb.compareTo(c)がともに正 ならa.compareTo(c)も正
さらに、オブジェクトが変化しない限りはなんど計算しても同一の答えを出さ
なければならない一貫性が求められます。
また、 a.compareTo(b)==0 の時、 a.equals(b)
が true であることが推奨されています。
このように全ての要素が比較可能で、上記の全順序の条件が成り立つ場合、必 ず、各要素は数直線のように一次元に並べることができます。 そのため、上記の条件を満たすような比較のことを全順序関係と呼びます。
なお、半順序関係とは全順序の条件に対して比較不能を許すもの です。 この場合、一直線上には並ばなくなります。 例えば、「約数である」という条件は半順序関係です。 この場合、反射律、推移律などは満たしますが、 任意の自然数の組に関して、反対称律は必ずしも成り立ちません。
例2-3
例2-1 では顧客の等価条件を顧客の ID と定めましたので、 顧客の ID を順序として与えます。
class Customer implements Comparable<Customer>{
private String id;
...
/**
* 顧客の順序を与えます。
* @param 顧客オブジェクト
* @return 大小関係に応じて 負値(小), 0(等), 正値(大) を返します。
*/
public int compareTo(Customer customer){
return this.id.compareTo(customer.id);
}
}
このように Comparable を実装すると、 TreeSet に格納すると自然に整列さ れる他、配列に対しては java.util.Arrays.sort メソッドで整列できますし、 各 Collection に関しても Collections.sort メソッドで整列可能です。 なお、 TreeSet や TreeMap を使用する場合、compareTo が 0 であることと、 equals が true になることが一致していないと誤動作します。
import java.util.LinkedList;
import java.util.Collections;
final LinkedList<Customer> customerList = new LinkedList<Customer>();
customerList.add(new Customer("..."));
...
Collections.sort(customerList); // Customer が Comparable なので整列される
比較子(Comparator)
オブジェクトの集まりを比較するとき、もともと与えた順序と異なる順序を考 えたい場合があります。 例えば、顧客番号以外に、名前順、購入金額順、成績順など、 さまざまな順序による整列(sort)は多くの情報処理における基本的な操作です。 オブジェクト指向言語ではこのような整列を行うために、Comparator(比 較子)と呼ばれるオブジェクトを作り、整列のメソッドに渡す手法が一 般的です。
Java で比較子を作るには、 java.util.Comparator インターフェイスを implement し、compare メソッドを実装します。
package java.util;
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
この compare は二つのオブジェクトを引数に取り、左が小さければ負の整 数、等しければ 0、左が大きければ正の整数を返します。
例2-4
例えば、顧客リストに関して生年月日で順序付けを行いたい場合を考えます。 顧客の生年月日は getBirthDay メソッドで java.util.Date 型の誕生日を取 得できます。 また、 java.util.Date 自体が Comparable なので、 compareTo メソッドは 既に実装されています。 そのため、比較子は顧客オブジェクトから誕生日を取り出して、 compare に与えるだけで実現できます。
import java.util.Comparator;
class BirthDayOrder implements Comparator<User> {
public BirthDayOrder(){}
public int compare(User u1, User u2){
return u1.getBirthDay().compareTo(u2.getBirthDay());
}
}
顧客の配列があったとして、これを誕生日順に並べるには次のようにします。
User[] userList;
...
java.util.Arrays.sort(userList,new BirthDayOrder());
なお、 java.util.Comparator インターフェイスには equals メソッドも実装 するように定義されていますが、全てのクラスは java.lang.Object のサブク ラスですので、デフォルトの equals は既に実装されています。 そのため、マニュアルにあるように通常は equals は実装しません。 この equals は要素の等価性を判定するものではなく、比較子の等価性を判定 するものです。
2-3. 演習問題
演習2-5
-
科目名(String)ごとに点数(Integer)を持つ 成績(Seiseki)クラスを java.util.HashMap のオブジェクトをコンポジション で持つだけのクラスとして作りなさい。
実装するメソッドは次のメソッドです。メソッドの詳細は java.util.HashMap と同様ですので API のマニュアルをよく参照して実装しなさい。
- put(String,Integer)
- 科目ごとの成績の追加
- get(String)
- 科目を指定して成績を得る
- containsKey(String)
- 科目を習得しているかどうかを調べる
- entrySet()
- Map の Set ビューを返す
- keySet()
- キーの Set ビューを返す
-
1 で作成したクラスに対して、平均点を返す double getAverage() メソッドを実
装しなさい。そして、次のプログラムと結合してテストを行いなさい。
import java.util.Map; class Ex1 { /** 成績と平均点を表示します。 * @param Seiseki オブジェクト */ private static void showSeiseki(Seiseki s){ for(Map.Entry<String,Integer> item : s.entrySet()){ System.out.println(item.getKey()+": "+item.getValue()); } System.out.println("平均: "+s.getAverage()); } public static void main(String[] arg){ final Seiseki student1 = new Seiseki(); final Seiseki student2 = new Seiseki(); student1.put("データ構造とアルゴリズムI",70); student1.put("データ構造とアルゴリズム2",80); student1.put("情報ネットワーク",100); student2.put("データ構造とアルゴリズムI",90); student2.put("データ構造とアルゴリズム2",70); student2.put("情報ネットワーク",60); showSeiseki(student1); showSeiseki(student2); } }
演習2-6
演習2-5 のように 成績と Java のデータ構造である Map の関係は通常は has-a 関係になります が、成績を単なる表を表すオブジェクトとみなす場合、 is-a 関係として解釈できることも あります。 そこで、成績を単なる表だと思って、 HashMap のサブクラスとして実装して みましょう。 科目名(String)ごとに点数(Integer)を持つ 成績(Seiseki)クラスを java.util.HashMap<String,Integer> のサブク ラスとして作りなさい。 そして、 double getAverage() を実装して、演習2-5 の 2 と同じプログラムに結 合しなさい。
演習2-7
演習2-5 において、成績を student という変数名で受けるのには違和感があ ります。 学生ごとに成績があるということは、学生(Student)と成績(Seiseki)がオブジェ クトになり、has-a 関係があることになります。 また、学生には学籍番号があるとします。 そのため、 setId, getId, getSeiseki を実装しなさい。 なお、Student のコンストラクタで成績オブジェクトを初期化しなさい。 また、さらに、 Student クラスでは学籍番号順に扱いたいので、 equals, hashCode, compareTo メソッドを実装しなさい。 そして、下記のプログラムと結合して動作を確かめなさい。 但し、Seiseki クラスは演習 1, 2 のどちらのものでも構わない。
import java.util.Map;
class Ex3 {
/** 成績と平均点を表示します。
* @param Seiseki オブジェクト
*/
private static void showSeiseki(Seiseki s){
for(Map.Entry<String,Integer> item : s.entrySet()){
System.out.println(item.getKey()+": "+item.getValue());
}
System.out.println("平均: "+s.getAverage());
}
/** Student オブジェクトの配列に対して、 id を表示します
* @param Student[] 型の配列
*/
private static void showStudentId(Student[] array){
for(Student student : array){
System.out.println(student.getId());
}
}
public static void main(String[] arg){
final Student[] students = new Student[3];
for(int i=0; i < students.length; i++){
students[i] = new Student();
}
students[0].setId("07ec999");
students[1].setId("07ec990");
students[2].setId("07ec995");
students[0].getSeiseki().put("データ構造とアルゴリズムI",70);
students[0].getSeiseki().put("データ構造とアルゴリズムII",80);
students[0].getSeiseki().put("情報ネットワーク",100);
showSeiseki(students[0].getSeiseki());
showStudentId(students);
java.util.Arrays.sort(students);
showStudentId(students);
}
}
演習2-8
次のクラス ThreeInt には、コンストラクタで 3 つの要素を持つ int[] 型の 配列を与えて使用します。
import java.util.*;
class ThreeInt {
private int[] array;
public ThreeInt(int[] a){
array = a;
}
public int getFirst(){
return array[0];
}
public int getSecond(){
return array[1];
}
public int getThird(){
return array[2];
}
@Override public String toString(){
return Arrays.toString(array);
}
}
下記のプログラムにおいて、Arrays.sort を行ったとき、 Third のインスタンスを与えれば 3 番目の要素に対して整列、 First のインスタンスを与えれば 1 番目の要素に対して整列、 Second のインスタンスを与えれば 2 番目の要素に対して整列するように、 それぞれ Comparator<ThreeInt> としてクラスを作りなさい。
class Ex {
private static void show(ThreeInt[] array){
for(ThreeInt t : array){
System.out.println(t);
}
System.out.println("---------");
}
public static void main(String[] arg){
final ThreeInt[] tArray = { new ThreeInt(new int[]{1,2,3}),
new ThreeInt(new int[]{2,3,1}),
new ThreeInt(new int[]{3,1,2})};
show(tArray);
Arrays.sort(tArray, new Third());
show(tArray);
Arrays.sort(tArray, new First());
show(tArray);
Arrays.sort(tArray, new Second());
show(tArray);
}
}
出力例
[1, 2, 3] [2, 3, 1] [3, 1, 2] --------- [2, 3, 1] [3, 1, 2] [1, 2, 3] --------- [1, 2, 3] [2, 3, 1] [3, 1, 2] --------- [3, 1, 2] [1, 2, 3] [2, 3, 1] ---------
2-4. 付録
演習2-1のファイル
spro2/A.java
package spro2;
public interface A {
String name();
String id();
}
spro2/AbstractA.java
package spro2;
public abstract class AbstractA implements A {
@Override
public String toString() {
return id()+":"+getClass()+":"+name();
}
}
spro2/A999A.java
package spro2;
public class A999 extends AbstractA {
@Override
public String name() {
return "坂本直志";
}
@Override
public String id() {
return "99ec999";
}
}
spro2/Main.java
package spro2;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
A[] list = {
new A999(),
};
Arrays.stream(list)
.forEach(System.out::println);
}
}