|
このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
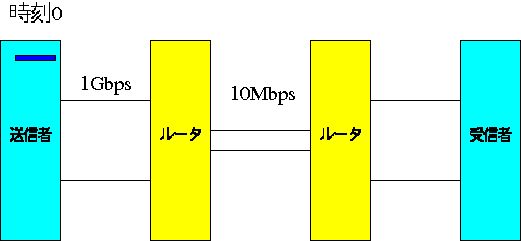
送信者が通信量を制限しない場合、どのようなことが起こるでしょうか。 ここでは送信者、受信者とも 1Gbps のネットワークにつながっており、中間 に 10 Mbps のネットワークがあったとしましょう。 TCP の接続の時、受信者は 1Gbit を同時に受信可能と送信者に報 告したとします。 このとき、送信者がその値を真に受けて、1Gbit まで同時に送るとどのような ことが起きるでしょうか?
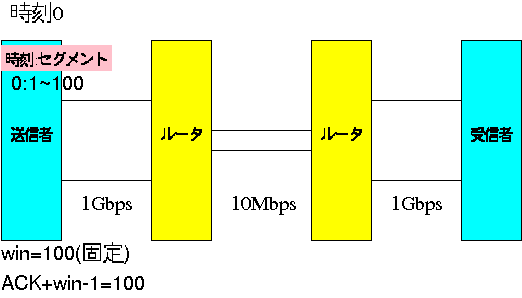
前回のセルフクロックではルータに理想的なバッファがあることを仮定してま した。 このような仮定では、セルフクロックによりもっとも遅いネッ トワークである 10Mbps に伝送速度が調整されることを前回説明しました。 しかし、現実には IP ネットワークでは IP パケットの通信保証をしなくて良いことに なっており、バッファから溢れたパケットはすべて破棄されます。 ここではルータのバッファサイズを 0.1 秒分=100Mbit とします。 このような状況で、送信側の送信ウィンドウは受信者から送られてきたウィン ドウサイズに固定し、またタイムアウト時間を勝手に固定することを考えます。 ここでは仮にそれぞれ 1Gbps と 30秒 であるとします。 すると以下のように非常に効率の悪い状況が発生します。
|
|
|
タイムアウトの短さにより再送しているもののほとんどが無駄になっているこ ともわかりますが、その原因は一度に送る量が途中の通信速度を越えていることが 全てです。 つまり、送信側で送信量を絞らない限り、不要なパケットを送っては捨てられ ることを繰り返すことになります。 このような通信容量を越える送信は一対一通信の非効率性を招くだけでなく、 不要なパケットを大量に送出することになるので、ネットワークを共有してい る他者にも迷惑をかけることになります。 今回はこの送信者の送信量の制限による通信効率の向上について考えます。 そのために使用される技術は送信ウィンドウ制御と、タイムアウト時間の制御 です。
送信側では、途中のボトルネック、つまりもっとも 遅いネットワークの処理できる数程度に、一度に送るセグメント数を落す必要があります。 そうしないと、ボトルネックで輻輳が起こります。 送信側のこのような一度に通信できる上限値のことを輻輳ウィンドウサイズ と呼びます。 記号で cwndと書くことがありますのでここでもそれに従います。
輻輳ウィンドウサイズcwndの制御は主に受信者からの ACK 情報で 行います。 これは、有線ネットワークでのパケットロスの原因のほとんどは輻輳によるか らです。 ですから、基本的にはパケットロスを検知したら、輻輳ウィンドウサイズを小 さくする方針をとります。
1988 年に発表された TCP Tahoe は次のようなアルゴリズムで輻輳制御を行って います。
もっとも単純な発想として、輻輳を検出したら輻輳ウィンドウサイズを 1 に してしまう手があります。 但し、高速なネットワークに対しても、1 から始めることになるので、効率よ く通信を行うには、急速に輻輳ウィンドウサイズを増やす必要があります。 そこで、指数関数的に増やすことを考えます。 ある時点で cwnd 個のセグメントを送った時、輻輳が起きなければ次は 2cwnd 個のセグメントを送りたい場合、どのようなプロトコルになるでしょう か? 基本的に送信者のわかる情報は ACK の観測だけです。 輻輳が起きなければ ACK はすべて返ってきます。 cwnd 個のセグメントを送ると cwnd 個の ACK が返ってきますので、この情報 を元に cwnd を 2cwnd にするためには一つの ACK 毎に cwnd を 1 だけ増や せばいいことになります。 このように 1 から指数関数的に cwnd を増やすために、 ACK 毎に cwnd を 1 ずつ増やすアルゴリズムをスロースタートと言います。
スロースタートにより cwnd は指数関数的に増えるため、ホストの性能が途中 の通信回線より高速な場合、いつかは必ず輻輳が発生します。 そのためスロースタートを途中で止め輻輳を回避する必要があります。 スロースタートである cwnd では輻輳が起きず、 2cwnd で輻輳を検知したと すると、次回も同様の状況になると予想できます。つまり、 cwnd 以上 2cwnd 以下のパケット同時送信で輻輳が起きると予想できます。 そこで、輻輳を検知した時の cwnd(上の 2cwnd) の半分の値を覚え ておき(変数名 ssthresh)、次回のスロースタートの時、 cwnd の値が ssthresh に達したら輻輳回避モードに移行するようにします。
輻輳回避モードに移行したら何をすれば良いでしょうか? cwnd を固定してしまう手もありますが、輻輳検知をミスし、ただたまたまパ ケットロスが起きただけの場合でも cwnd が固定されてしまうおそれがありま す。 そのため、cwnd は緩やかに増えるべきです。 そこで、cwnd 個のセグメントを送った後、次回は cwnd+1 個のセグメントを 送ることを考えます。 スロースタートで考えた時と同様、 ACK 一つ当たりで増やすべき値を考えま す。 ACK は全部で cwnd 個返ってきてこれで cwnd を 1 増やすことになるので、 ACK 一つ当たりの増やす量は単純に考えれば 1/cwnd になります(逐次的に増 やす場合は毎回 cwnd が書き変わるので、実際に増える量は少なくなる)。
有線ネットワークではパケットロスの原因のほとんどは輻輳です。 また、ほとんどのパケットは順番に流れると仮定できます。 このような仮定において、複数回同じ ACK が返ってくることを指 す重複 ACKという状態 は何を示していることになるので しょうか? 例えば、セグメント 101 の ACK が返ってくると言うことは、セグメント 100 までは連続して受信できたことを意味します。 次に、もう一度同じ ACK が来たと 言うことは、101 セグメントを受信せず、 102 以上のセグメントを受信した ことを意味します。 つまり、セグメントが連続して送られる確率が高いという仮定により、重複 ACK という状態はセグメントを失った確率が高いことを意味します。 また、セグメントを失ったと推測できるなら、それは輻輳が起きていることが 原因だと推測されます。
このような考察から、三回同じ ACK が来る時(トリプルACK)は、 その ACK で示されるセグメントのパケットは失ったものと結論し、そのセグ メントを再送します。 このようにするとタイムアウトを待って再送するのに比べ高速に失ったパケッ トを補填できますので、 これを高速再送(Fast Retransmit)と言います。 さらに、トリプル ACK はパケットが消失していることを指し、有線ネットワー クではそれは輻輳が生じているのが原因と判断できるので、タイムアウトの他 にトリプルACKでも輻輳を検知します。
以上のようにスロースタート、輻輳回避モード、 Fast Retrasmit が組み込ま れた TCP が TCP Tahoe と言います。
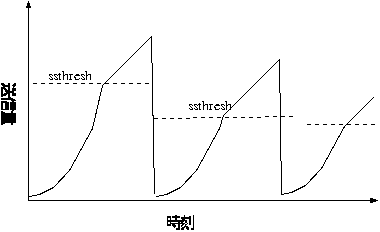
TCP Tahoe では輻輳を検知した時、スロースタートに移行してしまいます。 これは通信速度を落し過ぎなのではないでしょうか? TCP Reno はこれを改善しています。
タイムアウトによりパケットロスを検知した時は受信者と通信不能になってい る可能性もあるため、本当に cwnd を 1 にすべきです。 しかし、トリプル ACK による輻輳検知では、受信者と通信できているわけで すし、直前の cwnd では輻輳が起きなかったことがわかっています。 そこで、トリプル ACK により輻輳を検知した時、cwnd に 1 を代入せずに半 分にし、ssthresh も同じ値にします。 そしてスロースタートではなく輻輳回避モードで通信を行います。 このようにすると、実際の回線容量の半分以下にならずに通信を続けることが できます。 これを高速リカバリ(Fast Recovery)と言います。
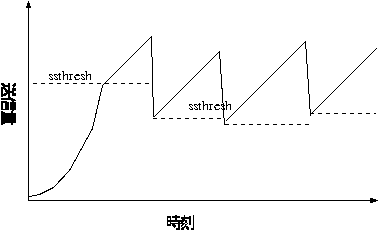
パケットが何らかの原因で失なわれたとしても、検知する側は即座に判断でき るわけではなく、ある程度の時間内に受け取れなかった時にはじめて判断でき ます。 そのため、タイムアウト時間を設定し、その時間内に ACK が来なければパケッ トを失ったと判断することにします。 但し、このタイムアウト時間が短過ぎると、相手が既に受け取っているパケッ トまで重複して送ることが起きうるため、 ネットワークの輻輳を引き起こすかも知れません。 一方、長過ぎるとパケットを失ったと判断するまでの時間が長くなり、再送す るまでの時間も長くなります。すると結局は伝送速度を大きく落すことになっ てしまいます。 そのため、適切なタイムアウト時間を定める必要があります。 TCP では動的にこのタイムアウト時間を計算します。
データリンク層ではネットワークが直接つながっているため、パケットの伝送 はある意味物理現象に支配されています。従って、受信者にパケットが届き、 ACK が返ってくるまでの平均時間(Round Trip Time RTT)の理論値 は比較的正確に求められ、誤差も少ないです。 しかし、複数のネットワークをルータにより経由するネットワーク層ではそう は行きません。 輻輳が起こったり、ルータでバッファリングされたりするとパケットの伝送時 間が引き延ばされるため、受信者までの到着時間の平均値の誤差は非常に大き くなります。 ネットワークがすいている時は短い時間でパケットが往復しても、混んでいる 時は時間がかかることがあり、しかも時間のかかり方は予想しづらいものです。
このように一般に RTT の予想は難しく、また時間とともに変化します。 そこで、理論値から決定する方法ではなく、実測値を元に決定する方法を選び ます。 但し、RTT のモデルは平均値と偏差を持つような確率変数になるので、単純に 実データそのものをタイムアウト時間とすることはできません。 Jacobison は、経験的な値と実測値の重み付き平均を求める方法として以下を 推奨しました。
M を実測の RTT とし、時刻 t の予測 RTT を RTTt とし、予測偏差を Dt とします。
ただしここでαは 7/8 とします。
ここで、TCP の状態を考えます。 TCP は輻輳を検知して通信状態を変化させていますが、輻輳を検知した状態と そうでない状態において、RTT の計算方法が同一で良いかということです。 というのは、深刻な輻輳が生じている時は、そもそも RTT は観測できないか もしれません。 また、そういう場合はタイムアウト時間を大きく設定する必要があります。 したがって、輻輳検知状態とそれ以外で RTT の計算方法を変える必要があり ます。 これに対して、Karn は次のアルゴリズムを提唱しました。
Reno では輻輳検知をした後の再送モードで送信パケット数を抑制しすぎると いうバグが指摘されました。 TCP new Reno はそれを解消し、輻輳検知時もパケットを多く送るようにしま した。
TCP Reno まではパケットロスによって輻輳の検知を行ってました。 一方、TCP Vegas ではラウンドトリップタイムにより輻輳を検知します。 基本的には、過去の実績からラウンドトリップタイムを予想し、実際のラウン ドトリップタイムが短ければ輻輳ウィンドウを広げ、長ければ輻輳ウィンドウ を狭めるというものです。
TCP new Reno は必ず帯域以上の通信を行っ て、輻輳を起こすという性質があります。 そのため、 TCP Vegas と TCP new Reno などと共存すると、 TCP new Reno の起こす輻輳を TCP Vegas が検知してしまい、 TCP Vegas は輻輳ウィンドウ を狭めてしまいます。 つまり、TCP Vegas は TCP new Reno と共存すると、 TCP Vegas に帯域を譲っ てしまい、十分なパフォーマンスが出ないという指摘があります。
TCP new Reno はある程度の性能を発揮しましたが、上記のグラフでわかるように、効率は 75% 程度です。 そのため、輻輳回避モードの効率を上げるため、パケットロスを検知したとき、 半分よりも大きい値までしか下げないようにし、また、前回輻輳した cwnd まで急速に近づけ、さらに輻輳した付近ではゆっくり増加させるよう なチューニングを考えます。
TCP Cubic は輻輳回避モードで三次曲線を用いて前回パケット廃棄が起きた ウィンドウサイズまで復旧させますが、このとき、ackパケットに依存するのではなく、実時間を使って復旧させます。
Linux 2.6.19、Windows 10(RC2)、MacOSX 10.10 以降で TCP Cubicが採用さ れています。
TCP をプログラムから扱うにはどうすれば良いのでしょうか? TCP は、もともとファイルの転送を目的としたプロトコルですので、プログラ ムからはファイルの入出力と同様の取り扱いになると便利です。 TCP をファイルと同様に取り扱う為に開発された手法がソケット です。 クライアントはサーバを指定することでソケットを得て、そのソケットをファ イルハンドルのように使用して文字列を書いたり読んだりすることで通信を行 います。 従って、クライアントからはほとんどファイルと同様の手順で TCP の通信を 行うことができます。
一方、サーバーはもう少し複雑です。 サーバはクライアントを受け付けると言う仕事と、実際にクライアントにサー ビスを提供すると言う二つの仕事をします。 クライアントへサービスをしている間でも、他のクライアントを受け付けられ るように、通常、受け付け用のポート、プロセスと、サービス用のポートやプ ロセスは別になります。 この考え方をソケットに当てはめると次のようになります。
このような手順を踏むことになりますが、記述の仕方はプログラミング言語に 依存します。 但し、 OS レベルとしてはプリミティブ(基本操作)として次の動作が提供され ます。
import java.net.*;
class Rei {
pulic static void main(String[] args){
try{
Socket sock = new Socket(ホスト名 , ポート番号);
// Java ではソケットを得る段階で CONNECT する
// 但し、あらかじめソケットを作っておいてから
// CONNECT する方法もある
}catch(java.io.IOException e){
// 接続エラー処理
}
try{
java.io.InputStream is = sock.getInputStream();
java.io.OutputStream os = sock.getOutputStream();
// Java ではソケットそのものに入出力は行なわず、
// ストリームオブジェクトを介して行なう。
// is, os を使って入出力処理
}catch(java.io.IOException e){
// 入出力エラー処理
// sock.close() が必要な場合もある
}
try{
sock.close(); // DISCONNECT
}catch(java.io.IOException e){
// close 失敗
}
}
}
エラー処理は考えてません。
import java.net.*;
...
try{
ServerSocket serv = new ServerSocket(ポート番号); // LISTEN
for(;;){ // 無限ループ
Socket sock = serv.accept(); // 要求を受付け、新たなポートへのソ
// ケットを用意する
サービススレッド sth = new サービススレッド(sock);
sth.start(); // 実際のサービス開始
}
}
class サービススレッド extends java.lang.Thread {
private Socket sock;
サービススレッド(Socket _sock){ //コンストラクタ
sock = _sock;
}
@Override
public void run(){
// 実際のサービス
sock.close();
}
}