このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
ここからは正規文法で取り扱えないような言語を取り扱うため、正規文法より 強力な文法の記述法を学びます。
本講義で文法とは言語を定義するようなもの一般を意味してました。 しかし、通常、文法と呼ばれるものはもう少し形式が存在します。 英文法や国文法では、単語が品詞に分類でき、さらに文において品詞の並び方 が数通りに定められているという手法で定義されます。 例えば英語では、文は次の5文型になると言われています。
ここで S は主語、 Vは述語、Cは補語、Oは目的語です。
正規表現などはこのような表現ではありませんでした。 今回は、上記のように、文が特定の品詞の組み合わせでできているという ような文法表示を取り扱います。 このような表現による文法表現のしかた、正規文法との関係、プログラミング について学びます。 なお、 このような表現は、プログラミング言語や通信プロトコルの仕様の記述などに も利用されます。 そのため、利用価値が高いものです。
文法の与え方にはさまざまな方法がありますが、ここではバッカス・ナ ウア記法を取り上げます。 バッカス・ナウア記法は、 非終端記号の集合 VN、 終端記号の集合 VT、 ルール P、 開始記号 S∈VN の 4 つ組 で表します。
バッカス・ナウア記法では生成する文字列を作るアルファベットを 終端記号と言います。終端記号の集合を で表します。 一方、それに属さない記号を非終端記号と言います。 非終端記号の集合を で表します。 ルールは左辺に一つの非終端記号、右辺は非終端記号と終端記号の列で表しま す。通常は左辺と右辺は ::= や → という記号で結びます。 そして最後に一つ非終端記号を開始記号として指定します。 このルールで左辺に一つだけ非終端記号がある文法を 文脈自由文法と言います。
このように定義した文法において、つぎのような手順により記号列を生成しま す。
簡単のため、左辺が同じルールは、右辺を |(縦棒) で区切って列挙すること で一つにまとめることにします。
以下に簡単な文法の例を示します。
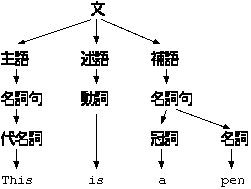
このようなルールから、 This is a pen という記号列が導けます。
このように終端記号と言っても一文字であるとは限りません。 通常は意味のあるひとまとまりの語句(トークン)毎に文法を考え ます。
正規文法では取り扱えなかった括弧も、このバッカスナウア記法では比較的簡 単に扱えます。 単純な括弧のみの言語は次のように書けます。
S→ε
S→SS
S→(S)
上記の文法にさらに [](角括弧)も使えるようにしなさい
バッカス・ナウア記法において、指定できるルールを「非終端記号→終端 記号, 非終端記号 → 終端記号 非終端記号」だけに制限した 文法を正規文法といいます。
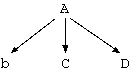
まず、このルールから非決定性オートマトンを構成できることを示します。 各非終端記号をそれぞれ一つのオートマトンの状態とします。 そして、開始記号である非終端記号を表す状態を開始状態とします。 また、別に終了状態を作っておきます。 A→bC 型の遷移規則に関しては、状態 A から入力 b で状態 C に遷移するよ うにします。 一方、 A→b 型の遷移規則に関しては状態 A から入力 b で終了状態に遷移す るようにします。 この様に構成するとすべてのルールは非決定性オートマトンの遷移規則に変換 できます。 さらに、構成した非決定性オートマトンがもとの文脈自由文法と同じ言語を受 理することが明かです。
逆に非決定性オートマトンがすべてこの文脈自由文法に変換できることを示す ことで、最終的に両者が等価であることを示します。 これは、上記の変換が一対一で行えることから、逆もまた可能であることを示 せば充分です。 つまり、任意の非決定性オートマトンに対して、状態 A から入力 b で状態 C に遷移するなら、非終端記号 A と C と終端記号 b に対して A→bC というルー ルを対応付ければ良いということです。 なお、受理状態への遷移に関しては、受理状態からεの入力を加えれば良いで す。 つまり A→bC というルールで C が受理状態なら、さらに C→ε を加えます。
以上により、この表記法と、以前に定義した正規表現が等価であることが示せ ました。
整数をこのバッカス・ナウア記法による正規文法により表現しなさい。
一般のバッカス・ナウア記法による記号列の生成では、一つの非終端記号が複数の 非終端、終端記号に対応します。そして、それに含まれる非終端記号がまた複 数の非終端、終端記号に対応します。 この導出の流れを図にすると、一つの非終端記号が複数の非終端、終端記号に 対応するので、木の構造になります。
根は開始記号になり、葉は終端記号、葉以外の頂点は非終端記号になります。 与えられた記号列に対して、それの生成手順に対応した木を構文解析木 と言います。 例えば、上の This is a pen という記号列は次のような構文解析木を持ちま す。
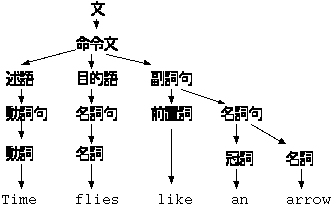
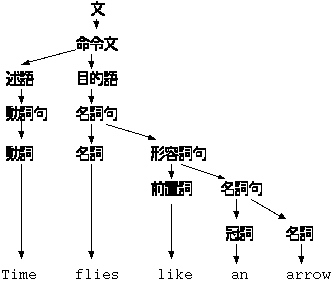
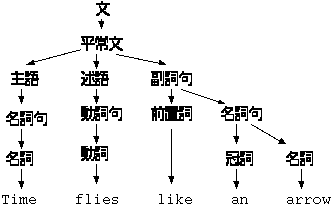
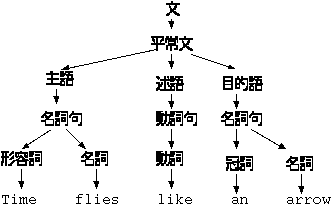
一つの記号列について、複数の構文解析木を持つ文法をあいまい であると言います。あいまいな文法はコンピュータで機械的に処理することが できません。 因みに英語はあいまいです。 次の文章の解釈はなんと 4 通りあります。
これは、動詞として Time, flies, like の三通りが考えられ、しかも Time が動詞の時は、 like an arrow の前が名詞になるので副詞句の他に形容詞句 になる可能性があるからです。
| 動詞 | like an arrow | 訳 | 構文解析木 |
|---|---|---|---|
| Time | 副詞句 | 矢のように蝿の所要時間を計りなさい |
|
| Time | 形容詞句 | 矢に似ている蝿の所要時間を計りなさい |
|
| flies | 副詞句 | 時間は矢のように飛ぶ |
|
| like | 時間蝿は一本の矢が好きである |
|
英語の場合、前後の文章や蝿、矢などに関する知識などを利用してふさわしい 訳を選ぶ必要があります。
自然言語の構文解析はとても難しいです。 次の日本語の構文解析木を書きなさい。
次の日本語を、前後関係などで構文を意識して、英訳しなさい
これは、料理屋で注文を確認された時に、発言した言葉です。
これは孫の誕生を話題にしている人同士の会話です。
足し算だけの数式を解釈する文法を考えます。 最初に次の文法を考えます。
=({和},{数, +}, P0, 和)
この文法では、 1+1 のような式は解釈できますが、 1+2+3 は駄目です。そこ で、足し算がいくつつながっていても解釈可能な文法を考えます。 数式は、一般に左から右へ解釈します。したがって、 1+2+3 は 1+2 を解釈し た後、その和に対して +3 を加えたものを新しい和とします。 つまり、次のようなルールが必要になります。
このルールがあれば、一番左の項以外はこれで解釈できます。 一番左の項はそれだけで和とみなせば 1+2+3 を解釈できます。
=({和},{数, +}, P1, 和)
なお、次のようにしてしまうと和の優先順序を指定できず、あいまいになりま す。
=({和},{数, +}, P1x, 和)
括弧を加えるにはどうしたら良いか考えなさい。
さて、文法からそれを解釈するプログラムを作 る手法を学びます。 なお、構文解析のことをparse、構文解析をするプログラムなどを parserといいます。
バッカス・ナウア記法の素朴な解析法として次のようなものがあります。 すべての非終端記号に対して、関数を作ります。 そして、左辺の非終端記号を関数呼び出しとし、右辺は関数の内部処理としま す。 そして、終端記号に対しては文字を認識し、非終端記号に関しては、それに対 応した関数を(再帰的に)呼び出します。 例えば、 A→bCD で A,C,D が非終端記号、 b が終端記号だった時、 関数 A を次のように作ります(あらかじめ文字を一つ読んでおきます)。
private boolean A(){
if(記号 b を認識できたら){
次の文字を読み込む
if(C()){
if(D()){
return true;
}
}
}
return false;
}
そして非終端記号 C, D に対しても同様に関数を作ります。 このようにすると構文木通りに関数が呼び出されて、与えられた記号列を処理 できる場合があります。 しかし、実際は一つの非終端記号から複数の導出規則が存在します。 例えば、下の例では状態 S で文字 a を読み込んだ時、 A か B のどちらを導 出するかはすぐには決められません。
素朴な方法としては、適当に導出規則を選び、途中で失敗したら別の導出規則 を選ぶ方法が考えられます。これをバックトラックと言います。 確かにこの方法でも構文解析できますが、しかし、キューを実装しているよう に、途中の入力を全て覚える必要があります。 また、考え得る全ての構文木を一つ一つ生成しては比較するようなものなので、 効率が悪いです。
A()||B() は A() を実行して true が返ってきたら B() は実行
されず true になります。
A() が false が返されたときだけ、 B() が実行されて、その値が返されます。
import java.io.*;
class Parser {
public Parser(Reader r){
reader = new BufferedReader(r);
}
final private BufferedReader reader;
public boolean S() throws IOException{
if(A() || B()){ // A がだめなら B
return true;
}else{
return false;
}
}
private boolean A() throws IOException{
reader.mark(2); // 2 文字読んだあと戻す可能性がある
if(reader.read()=='a' && reader.read()=='b'){
return true;
}
reader.reset();
return false;
}
private boolean B() throws IOException{
reader.mark(2);
if(reader.read()=='a' && reader.read()=='c'){
return true;
}
reader.reset();
return false;
}
}
class Rei {
public static void main(String[] arg) throws IOException{
Parser parser = new Parser(new InputStreamReader(System.in));
if(parser.S()){
System.out.println("Ok");
}else{
System.out.println("NG");
}
}
}
バックトラックを避け、効率良く構文解析するためにはどのようなことが考え られるでしょうか? 一つの考え方として、次に読み込む記号から必ず導出規則が一つ決定できるよ うな文法が与えられたとします。 そのような文法では文字を読み込みながら if 文でどちらの導出規則を選択で きるため、バックトラックを行わずに済みます。 この、どんな非終端記号に対しても、入力を左から読んでいき、次の先頭の文 字を読むだけで一意に導出が可能な文法を LL(1)文法 と言います。 (Left to Right, Leftmost derivation)
さて、足し算の文法をプログラムで表現する手法を考えます。 まず、前回の足し算の文法は以下の通りです。
=({和},{数, +}, P1, 和)
この文法は LL(1) ではありません。 つまり、この文法では上で述べたように、文字を読んでも次の導出規則を決 めることはできません。 なぜならば、入力列に対して というルールを適応するには、その先頭部分が「和」の形になってい るかどうかを調べる必要があります。そして、そのためにはその先頭部分が 「和」の形になっているかどうかを調べる必要があります。 このように解釈が巡回してしまい、結論にはたどり着けません。 つまり、左辺と同じ非終端記号が右辺の先頭に来ていると、入力 列を順に読む構文解析ができなくなります。 これを左再帰性と言います。
この左再帰性は次のようにすれば除去できます。 例えば、次のような左再帰性を持つ生成規則があったとします。
A は非終端記号で、α と β は非終端記号、終端記号からなる列を 表し、β は A で始まらないとします。 これは β, βα, βαα, ... という列を表 します。 この時、次のように書き直すと左再帰性がなくなります。
上の足し算を解釈する文法G1の左再帰性を除去すると次のように なります。
=({和, 和'},{数, +}, P2, 和)
さて、数式を計算させ、答えを求めたい場合、数式の最後を明白にする記号と して、 = を入力するというルールを追加します。 このルールを含めた文法 G1, G2 をそれぞれ G1', G2' とします。
=({和, 始},{数, +, =}, P1', 始)
=({始, 和, 和'},{数, +, =}, P2', 始)
文法に対して、左辺から右辺への導出が、次の一文字を読むだけで決定できれ ば、その文法をLL(1) 文法と言います。 これは、開始記号から導出を始め、一番左の非終端記号を次の入力文字から導 出ルールを一意に決められれば良いというルールです。 各非終端記号 A に対して、その導出規則が A→α と A→β であったと仮定します。 この時、 Director(A,α) を A→α において、この規則によ り一番左側に導出される可能性のある終端記号の集合とします。 この時、どの非終端記号 A に対して、 Director(A,α)∩Director(A,β)=∅という関係が全ての A からの導出規則について成立すれば、得られた終端記号列から一意にプログ ラムで構文解析ができます。
private boolean A(){
if(文字∈Director(A,α)){
return αの処理が成功したか;
}else if(文字∈Director(A,β)){
return βの処理が成功したか;
}...
return false;
}
ここで、Director 内で重複する終端記号はありませんので、文字はどこか一 つの Director にだけ属するだけです。 そのため、 α の処理などが失敗してもバックトラックの必要がありま せん。
さて、このような Director 集合の計算方法を与えます。 なおプログラムの処理では次の一文字を読んで次の動きを決めます。 そのため、終了判定を行うには終了したことがわかるように、入力文 字が終ったことを示す特殊な文字を考えることがあります。
LL(1)文法は次のように形式化できます。 α は非終端記号、終端記号からなる列とします。 また A は非終端記号とします。 この時 First(α), Follow(A), Director(A,α) を次のように定義 します。
文法 G2'についてこれらを計算すると次のようになります。
このように各非終端記号に対して、その生成規則を示す Director 同士 に共通部分がない文法を LL(1) 文法と言います。 G2' は 計算した Director に共通部分がないので LL(1) 文法です。 実際、Director(和',⋅) は {+} と {=} なので共通部分はありません。
なお G1' についても同様に計算すると次のようになります。
このように非終端記号「和」に対して、 Director(和, ・) に重複がありますの で、 LL(1)文法ではありません。
LL(1) 文法は、先に示した素朴な関数呼出による構文解析に対して、次に来る ものを判断して構文規則を変えることで構文解析ができるようになります。
import java.util.Arrays;
private boolean isContained(char c, char[] set){
// set はソートされている必要あり
return Arrays.binarySort(set,c)>=0;
}
private boolean A(){
if(isContaind(文字,new char[]{'x','y'}){
return B();
}else if(isContaind(文字, new char[]{'z'}){
次の文字を読む;
if(文字 == 'u'){
次の文字を読む;
if(C()){
if(文字 == 'w'){
return true;
}
}
}
}
return false;
}
G2' は LL(1) 文法なので、プログラムで構文解析できます。 同様に Director により次のように計算できます(わ かりやすいように日本語を使ってますので、このままでは動きません)。
private static boolean 始(){
if(次 == 数){ // Director(始,和=)={数}
if(和()){
if(次 == '='){
return true;
}
}
}
return false;
}
private static boolean 和(){
if(次==数){ // Director(和,数和')={数}
次を読む;
if(和'()){
return true;
}
}
return false;
}
private static boolean 和'(){
if(次=='='){ // Director(和',ε)
return true;
}else if(次=='+'){ // Director(和',+数和')
次を読む;
if(次==数){
次を読む;
if(和'()){
return true;
}
}
}
return false;
}
public static void main(String[] arg){
次を読む;
if(始()){
System.out.println("Ok");
}else{
System.out.println("NG");
}
}
上記のプログラムにおいて、「次==数」の判定方法が自明ではありません。 これまでのまとめとして、数字一桁の足し算の式を受理する(形を認識するだ けで計算しない)プログラムを示します。 文字を読み込むタイミングが、 Director の要素の判定時ではなく、判定を通っ た後の実際のルールの解釈時であることに注意します。
import java.io.*;
class Parser {
final private Reader reader;
public Parser(Reader r) throws IOException{
reader = r;
c = reader.read();
}
private int c;
public boolean s() throws IOException{
System.err.println("called s.");
if(Character.isDigit(c)){
if(wa1()){
if(c=='='){
c = reader.read();
return true;
}
}
}
return false;
}
private boolean wa1() throws IOException{
System.err.println("called wa1.");
if(Character.isDigit(c)){
c = reader.read();
if(wa2()){
return true;
}
}
return false;
}
private boolean wa2() throws IOException{
System.err.println("called wa2.");
if(c=='='){
return true;
}
if(c=='+'){
c = reader.read();
if(Character.isDigit(c)){
// 足し算の処理
c = reader.read();
if(wa2()){
return true;
}
}
}
return false;
}
}
class Rei {
public static void main(String[] arg) throws IOException{
final Reader r = new InputStreamReader(System.in);
final Parser parser = new Parser(r);
if(parser.s()){
System.out.println("accept");
}else{
System.out.println("reject");
}
}
}
なお Pascal というプログラミング言語は LL(1) 言語です。 したがって、 LL(1) は制限がきついですが、そこそこ実用的な文法まで表現 できます。
例4-3 では各関数で文字を読んでいました。 このような処理の仕方はこれまでのプログラムは構造が異なっています。 以下に構造を抽象的に示します。
public static void main(String[] arg){
前処理;
while(文字を読みつづける){ // 読み込みは一ヶ所
文字列の組み立て処理;
文字列が完成したら出力;
}
後処理;
}
class Parser {
private boolean 非終端記号1(){
if(トークン∈Director(非終端記号1,α)){
return α の処理;
}else if(文字∈Director(非終端記号1,β)){
return β の処理;
}...
return false;
}
private boolean 非終端記号2(){
トークンの列に応じて他の非終端記号を呼び出す;
return true;
}
...
}
/*
α や β の処理中で文字を読み、終了判定も考慮される。
*/
class Rei {
public static void main(String[] arg){
if(開始記号()){
System.out.println("受理");
}else{
System.out.println("拒否");
}
}
}
プログラムの基本的なテクニックとして、入力、出力、処理を分割すると言う 考え方があります。 長きに渡って使ってきた、「ループの冒頭で文字を読み、終了条件を判定し、 ループの中で出力作業を行う」というのは、確かにプログラミングの定石の一 つではあります。 しかし、今回のように複数の関数で共通のストリームから入力を読むという処 理を付加することができません。
以前、オートマトンも主プログラムのループ内で処理してましたが、これを改 め、呼び出すと字句が得られる関数を作ると便利です。 字句を取り出す関数を getword と呼ぶことにします。 これは Java の正規表現の group メソッドのような働きをするものです。 また、さらに今回は、「演算子」「数字」など複数の種類の字句を一つの getword で取り出す必要があります。 つまり、getword の返すものは字句の種類と、実際の字句を示す文字列である とします。
字句の定義はそれぞれの種類で別々にオートマトンで定義できれば、開始状態 からε遷移により分岐すれば一つにまとめられます。 これで最長一致により入力から字句を取り出すことを考えます。 このとき、主プログラム中の入力ループによる字句の取り出しとは違い、次の ふたつの問題があります。

字句の終端の判定は、基本的には字句に含まれない文字を読み込んだ時になり ます。 ここで、関数としては値を返して処理を主プログラムに戻すことになるのです が、問題は「字句に含まれない文字」の取扱いです。 この文字は次の字句に含まれる可能性があります。 したがって、関数が終了しても、次に関数が呼び出されたときに処理できるよ う、関数自体がオブジェクトのように記憶領域を持ちその文字から処理を開始 できるようにします。 なお、この考え方は、入力がキューである場合は、関数が記憶領域を持たなく ても、読み過ぎた入力を元に戻すという操作で実現できます。
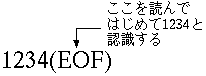
次にファイルの終端の処理です。 ファイルの終端を検出した場合、入力処理は終了ですが、そこで字句の検出も 終了し、関数としては返すべき値があることも考えられます。 つまり、ファイルの終端に達しても、関数は字句を戻すことがありえます。 この場合も、関数がファイルの終端を記憶しながら、字句を返し、次の呼出で、 字句を返せないことを示せばよいです。
このように、字句解析では、最長一致をするために、字句に含まれない次の文 字を読んだ後、次の呼出でもう一度読み出す必要があります。
さて、構文解析のプログラムから構文木を作ることを考えます。 ここでは文法 G2' のプログラム(例4-5, 例4-6)で考えます。 例4-5において G2' の 終端記号に対応するメソッドは s(), wa1(), wa2() です。 このうち、 s() は構文解析が終わった後、構文木を返すこととします。 構文木とは以下のようなものです。
この構造を作るのに、各頂点に対応するオブジェクト型として Node 型を考 えます。 上記のように構文解析木では数だけ入っている物と、演算子が入っていて子の 頂点が 2 つある物の二種類があります。 この二種類も新たなオブジェクトとみなし、それぞれ Kazu 型と Wa 型で表す ことにします。 すると、これらはどちらも Node でもあるので両方とも is-a 関係が成立しま す。 つまり、Kazu 型、 Wa 型ともに Node 型を継承しています。 したがって、とりあえず setter, getter のみしか示しませんが、各クラスは 以下のようになります。
class Node {
}
class Kazu extends Node {
private int value;
public Kazu(int n){
value = n;
}
}
class Wa extends Node {
private char op;
private Node left;
private Node right;
public Wa(){}
public void setOp(char op){
this.op = op;
}
public void setLeft(Node n){
left = n;
}
public void setRight(Node n){
right = n;
}
}
この定義では、親クラスの Node 型でメソッドが定義されていないので Wa ク ラスのメソッドが利用できなくなってしまいます。 そのため、 Node クラスには双方のメソッドを集めて abstract 宣言をしてお きます。
abstract class Node {
abstract public void setOp(char op);
abstract public void setLeft(Node n);
abstract public void setRight(Node n);
}
このようなクラスを用いて構文解析木を作ります。 まず、具体的な例として 以下の木を(手動で)作るプログラムを示します。
class Rei {
public static void main(String[] arg){
final Node tmp = new Wa();
tmp.setOp('+');
tmp.setLeft(new Kazu(1));
tmp.setRight(new Kazu(2));
final Node root = new Wa();
root.setOp('+');
root.setLeft(tmp);
root.setRight(new Kazu(3));
}
}
これで、変数 root が指しているオブジェクトとして構文解析木ができました。 最終的には、この作業を数式の構文解析プログラムに生成させます。 しかし、その前に、デバッグなどにも利用するため、構文解析木からの出力を考えます。
さて、ここで、このような状況に適合するデザインパターンを学びます。 上記の構文木は各 Node オブジェクト同士が互いに関連づいています。 この様な、同一のクラスのオブジェクトが関連付けられているような再帰的な 構造に対して、各オブジェクトから情報収集をするなど、次々とメソッドを動 作させるテクニックがコンポジットデザインパターンです。 なお、特に構文解析木から値など意味を抽出するために構文木から情報収集す る場合にインタプリタデザインパターンと言います。
コンポジットデザインパターンでは、線形リストや木構造などのデータ構造に おいて、すべての頂点が特定の親クラスを継承しているものとします。 そして、関係するすべてのクラスで同一メソッドを実装します。 その時、子の頂点に対して同一のメソッドを呼び出すことで再帰的にメソッド を実行します。 また、頂点のオブジェクト型に応じてポリモーフィズムが行われ、各頂点にふ さわしい動作が選択されます。
さて上記の構文木からもとの数式を取り出すことを考えます。 もとに戻してしまうため、一見何の意味もないように感じてしまいますが、 取り出せれば、構文解析のプログラムのチェックに使うことができます。 さて、これを実現するために、 Node, Wa, Kazu の各クラスに共通したメソッドを定義します。 ここでは、定義するのは showExpression メソッドとしましょう。 Kazu クラスでは単に保存されている数値を表示させることとします。 一方、 Wa クラスでは、演算子の左側の数式を表示してから、演算子を表示し、演算 子の右側をカッコを付加して表示します。 この様に実装したものを次に示します。
abstract class Node {
abstract public void showExpression();
}
class Kazu extends Node {
@Override
public void showExpression(){
System.out.print(value);
}
}
class Wa extends Node {
@Override
public void showExpression(){
System.out.print('(');
left.showExpression();
System.out.print(op);
right.showExpression();
System.out.print(')');
}
}
さて、同 様にしてデータ構造とアルゴリズム I で取り上げた逆ポーランド記法の表現 ができます。 では、ここで式の記述法について復習をしましょう。 通常の数式は演算子の両側に数値を記入します。 しかし、この演算子と二つに数値の関係に関して意味を変えず、表現を変える ことができます。
例えば、「add 1 and 2」など演算子を前に書くのを「前置記法」と言います。 これは例えば ((1 + 2) + 3) なら (+ (+ 1 2) 3) と書けます。 この記法は通常のコンピュータのプログラムに多い「命令 引数1 引数2」の記 法と共通です。 そのため構文としてこれしか持たないような Lisp などの言語で使われていま す。
一方、演算子を後ろに書くのが「後置記法」ですが、これは特に 逆ポーランド記法と呼ばれます。 例えば ((1 + 2) + 3) なら ((1 2 +) 3 +) となります。 この記法の特徴は、演算子の直後に閉じ括弧があるということです。 これは、演算子があれば、そこで注目すべき演算が完結することを意味します。 そのため、直前の二つの確定した値を引数にして演算を実行すれば計算ができ ます。 さらに、このため、上記の数式の表現に対してすべてのカッコを取っても演算 のしかたに曖昧さが生じません。 つまり 1 2 + 3 + などと表現すればよいことになります。 また、直近の値を取り出せば数式を計算できるため、スタックというデータ構 造を使えば数式の値を計算できます。
では、上記のデータ構造に対して逆ポーランド記法を出力するメソッド rpn (reverse Polish notation)プログラムを示します。 これは単に表示順序を「(左+右)」から「左 右 +」に変更するだけなので、下 記のようになります。
abstract class Node {
abstract public void rpn();
}
class Kazu extends Node {
@Override
public void rpn(){
System.out.print(value+" ");
}
}
class Wa extends Node {
@Override
public void rpn(){
left.rpn();
right.rpn();
System.out.print(op+" ");
}
}
前置記法を表示するメソッドを作成しなさい。
さて、構文解析の手続きにおいて、前節で定義したデータ構造による構文解析 木を返すプログラムを考えます。 これは構文に意味を与えることになります。
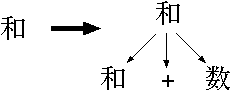
始めに G1 を考えます。 各ルールで、次のように木が作られます。
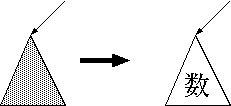
| ルール | 機械的な構文解析木 | 数式の構造 |
|---|---|---|
|
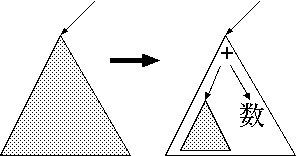
|
|
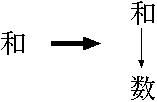
|
|
和の部分を考えると、導出により木の下の方に移動していくので、上から下へ 木を作っていきます。 もし、この形で構文解析出来るのであれば、プログラムは単純になります。 というのは、 + の両側が一つのルールの中で完結するからです。
/* G1 による構文解析木(ただし動作しない)
エラー処理はかなり適当
*/
class Parser {
public Node wa(){
if(入力が適合){
Node result = new Wa();
result.setLeft(wa());
result.setOp(lastChar);
nextChar();
result.setRight(kazu());
return result;
}
return null;
}
public Node kazu(){
if(入力が適合){
return new Kazu(lastChar);
}
return result;
}
}
しかし、これは左再帰性があるため、動作しません。
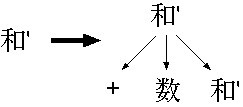
一方 G2 は次のように木が作られます。
| ルール | 機械的な構文解析木 | 数式の構造 |
|---|---|---|

|
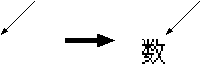
|
|
|
|
|
| そのまま |
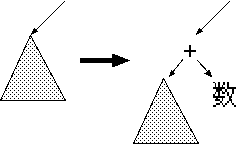
G2は左側に終端記号が来ます。 文字列は左から読むのでこれはどんどん木に対して終端記号を対応づけていく ことになります。 つまり G2では、下から上へ木を作ることになります。 また、一つの非終端記号のルールで演算子の左右が導出されません。 特に「和'」では ε か +数和' のどちらかになりますが、 ε では数式は終了しますが、 + があれば新しい親ノードが生成されなければな りません。 これは作りかけの構文解析木に対して、それで終了するか、それを左側にした 新たな親ノードを作るかです。 これを実現させるには、木の根の参照を書き換える必要があるので、構文解析 木の管理においてメソッドから書き換え可能になっている必要があります。 そのため、 Parser のメンバ変数で持つことにします。 また、木の参照を与えると、その木を左に持つような親頂点を返すような頂点 のファクトリメソッドを作ります。
それでは話をまとめます。 まず、 Parser のメンバ変数として、 Node 型の変数 root を持つことにしま す。 そして、 Wa クラスに次のようなファクトリを用意します。
class Wa extends Node {
public static Node connectToLeft(Node n){
final Wa result = new Wa();
result.setLeft(n);
return result;
}
}
そして、上記の処理を実装したのが以下のプログラムになります。 これにより、数式を逆ポーランド記法に変換するなどが可能になります。 なお、トークンの取り出しはやっていないので、数値は 1 桁のみしか取り出 せません。
import java.io.*;
class Parser {
final private Reader reader;
public Parser(Reader r) throws IOException{
reader = r;
c = reader.read();
}
private int c;
private Node root;
public Node s() throws IOException{
if(Character.isDigit(c)){
if(wa1()){
if(c=='='){
c = reader.read();
return root;
}
}
}
return null;
}
private boolean wa1() throws IOException{
System.err.println("called wa1.");
if(Character.isDigit(c)){
root = new Kazu(c-'0');
c = reader.read();
if(wa2()){
return true;
}
}
return false;
}
private boolean wa2() throws IOException{
System.err.println("called wa2.");
if(c=='='){
return true;
}
if(c=='+'){
char op = (char) c;
c = reader.read();
if(Character.isDigit(c)){
root = Wa.connectToLeft(root);
root.setOp(op);
root.setRight(new Kazu(c-'0'));
c = reader.read();
if(wa2()){
return true;
}
}
}
return false;
}
}
class Rei {
public static void main(String[] arg) throws IOException{
final Reader r = new InputStreamReader(System.in);
final Parser parser = new Parser(r);
Node tree = parser.s();
if(tree !=null){
tree.showExpression();
tree.rpn();
}
}
}
以上の議論により、数式(足し算のみ)を前置記法に変換するプログラ ムを作りなさい。
次回は JavaCC を使います。 インストールしておいてください。
@echo off
java -classpath (JavaCCを展開したフォルダの絶対パス)\bin\lib\javacc.jar javacc %1 %2 %3 %4 %5 %6 %7 %8 %9
残念ながら、2019年5月現在、Intellij IDEA で JavaCC を起動できません。 単にソースコードに色を付けることができるだけです。
@echo off
java -classpath (JavaCCを展開したフォルダの絶対パス)\bin\lib\javacc.jar javacc %1 %2 %3 %4 %5 %6 %7 %8 %9
なお、;(JavaCCを展開したフォルダの絶対パス)\bin
を追加する。
@echo off
set PATH=%PATH%;c:\javacc-5.0\bin
cd \work
cmd
abstract class Node {
abstract public void setOp(char op);
abstract public void setLeft(Node n);
abstract public void setRight(Node n);
abstract public void showExpression();
abstract public void rpn();
}
class Kazu extends Node {
private int value;
public Kazu(int n){
value = n;
}
@Override
public void showExpression(){
System.out.print(value);
}
@Override
public void rpn(){
System.out.print(value+" ");
}
}
class Wa extends Node {
private char op;
private Node left;
private Node right;
public Wa(){}
public void setOp(char op){
this.op = op;
}
public void setLeft(Node n){
left = n;
}
public void setRight(Node n){
right = n;
}
public static Node connectToLeft(Node n){
final Wa result = new Wa();
result.setLeft(n);
return result;
}
@Override
public void showExpression(){
System.out.print('(');
left.showExpression();
System.out.print(op);
right.showExpression();
System.out.print(')');
}
@Override
public void rpn(){
left.rpn();
right.rpn();
System.out.print(op+" ");
}
}
import java.io.*;
class Parser {
final private Reader reader;
public Parser(Reader r) throws IOException{
reader = r;
c = reader.read();
}
private int c;
private Node root;
public Node s() throws IOException{
if(Character.isDigit(c)){
if(wa1()){
if(c=='='){
c = reader.read();
return root;
}
}
}
return null;
}
private boolean wa1() throws IOException{
System.err.println("called wa1.");
if(Character.isDigit(c)){
root = new Kazu(c-'0');
c = reader.read();
if(wa2()){
return true;
}
}
return false;
}
private boolean wa2() throws IOException{
System.err.println("called wa2.");
if(c=='='){
return true;
}
if(c=='+'){
char op = (char) c;
c = reader.read();
if(Character.isDigit(c)){
root = Wa.connectToLeft(root);
root.setOp(op);
root.setRight(new Kazu(c-'0'));
c = reader.read();
if(wa2()){
return true;
}
}
}
return false;
}
}
class Rei {
public static void main(String[] arg) throws IOException{
final Reader r = new InputStreamReader(System.in);
final Parser parser = new Parser(r);
Node tree = parser.s();
if(tree !=null){
tree.showExpression();
tree.rpn();
}
}
}