このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
決定性オートマトンは次の状態への遷移が曖昧ではありません。 そのため、これをプログラムにするのは簡単です。 一番素朴なのは状態をラベルに対応させ、各遷移を goto 文で表現する方法で す。 但し、 Java では goto は予約語になっていますが使えません。 そこで利用するのはループ中で switch 文により状態と case を対応させる方 法です。 各状態ごとのプログラムをそれぞれ case に分けて納めます。 そして、どのプログラムを実行するかを選択するため、状態を表す変数を用意 します。 そして、この状態を表す変数を各プログラムの最後で次に移る状態に書き換え ます。
なお、このような有限個の状態を変数で表したい時などに使用する機能として、 列挙型があります。 Java の列挙型はクラスの拡張になっていて非常に強力です。 しかし、とりあえず C や C++ と同じ、単なる特定の値を名前で表す方法とし て学びます。 列挙型の宣言の方法は次のとおりです。
enum 列挙型名 { 要素1, 要素2, ..., 要素n }
このようにすると、列挙型名で宣言した変数は要素1, ..., 要素n のどれかの 値を取ることができます。 enum の中にもメソッドを書くことができますが、外部からアクセスする時に は値に対して 列挙型名.要素k などと、クラスの static メンバのような指定 方法を取ります。 但し、 switch case 文では列挙型名は不要です。
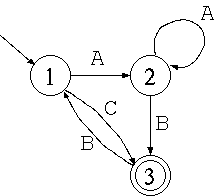
次の決定性オートマトンをプログラムにしたのが下記のプログラムです。
import java.io.*;
enum State {
STATE1, STATE2, STATE3
}
class Rei {
private static int get(Reader r) throws IOException {
int c;
do{
c=r.read();
}while(c=='\n' || c=='\r');
return c;
}
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
State s=State.STATE1;
try{
while((c=get(r))!=-1){
switch(s){
case STATE1:
if(c=='A'){ s=State.STATE2; }
else if(c=='C'){ s=State.STATE3; }
else{ throw new IllegalStateException(); }
break;
case STATE2:
if(c=='A'){ s=State.STATE2; }
else if(c=='B'){ s=State.STATE3; }
else{ throw new IllegalStateException(); }
break;
case STATE3:
if(c=='B'){ s=State.STATE1; }
else{ throw new IllegalStateException(); }
break;
}
}
if(s!=State.STATE3){
throw new IllegalStateException();
}
System.out.println("Accept");
}catch(IllegalStateException e){
System.out.println("Reject");
}
}
}
自然数を受理する決定性オートマトンを作り、それをプログラムに直しなさい。
Java の列挙型では、各要素毎にコンストラクタを起動させり、メソッドを持 てたりします。 さらに共通のメソッドを持たせ、抽象メソッドを定義させるとポリモーフィズ ムを利用することができるため、 switch case 文を取り除くことができます。
前述の例と等価で switch case 文を取り除いたプログラムを示します。 但し、これは Java 特有の機能で、他の言語にはあまり無いと思われます。
import java.io.*;
enum State {
STATE1 {
public State nextState(int c) throws IllegalStateException {
if(c=='A'){ return STATE2; }
if(c=='C'){ return STATE3; }
throw new IllegalStateException();
}
},
STATE2 {
public State nextState(int c) throws IllegalStateException {
if(c=='A'){ return STATE2; }
if(c=='B'){ return STATE3; }
throw new IllegalStateException();
}
},
STATE3 {
public State nextState(int c) throws IllegalStateException {
if(c=='B'){ return STATE1; }
throw new IllegalStateException();
}
};
abstract public State nextState(int c) throws IllegalStateException;
}
class Rei {
private static int get(Reader r) throws IOException {
int c;
do{
c=r.read();
}while(c=='\n' || c=='\r');
return c;
}
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
State s=State.STATE1;
try{
while((c=get(r))!=-1){
s = s.nextState(c);
}
if(s!=State.STATE3){
throw new IllegalStateException();
}
System.out.println("Accept");
}catch(IllegalStateException e){
System.out.println("Reject");
}
}
}
本章では非決定性オートマトンが決定性オートマトンに変換できることを示し ます。
非決定性オートマトンでは一つの状態から複数の状態へ遷移します。 そして、次々と遷移した後、一つでも受理状態へ遷移する遷移の仕方があれば 入力を受理します。 そこで遷移可能な状態のリストを考えます。そのリストの各要素に対して、入 力を適用して、遷移可能な状態のリストを作ります。 非決定性オートマトンではあらかじめ状態数が決まってますので、遷移可能な 状態のリストも全状態の中から選ぶことで作れます。したがって、遷移可能な 状態のリストの数も有限個になります。 例えば、非決定性オートマトンの状態として 1, 2 ,3 の三つの状態があった とします。 その時、遷移可能な状態のリストは、{1}, {2}, {3}, {1,2}, {2,3}, {1,3}, {1,2,3} の七通りになります。 そして、これらのリスト同士の間で、入力が与えられた時、どのリストへ遷移 可能かを考えます。 このように、遷移可能な状態リスト間で、入力による相互の移り変わりを決め ることができます。これは、入力により一意に次のリストが決まるので、決定 性オートマトンになります。 開始状態一個だけのリストを新たな開始状態とし、もとの受理状態を含むすべ てのリストを新たな受理状態とします。
ではここで例を示します。 例えば、正規表現 .*aab を受理する非決定性オートマトンは次のようになり ます(簡単のため、入力アルファベットを a と b に限ってます)。
このように先頭に任意の文字列の存在を許す正規表現は、長い文字列において aab とマッチする任意の箇所で受理状態になりますので、受理した回数を数え ることでマッチする個数を知ることができます。
さて、この非決定性オートマトンを決定性オートマトンに変換します。 但し、開始状態から到達可能な状態だけしか必要ないので、開始状態から処理 を始めて、必要な状態のみを書き出します。
| 状態リスト | 入力 | 遷移先の状態リスト |
|---|---|---|
| 1 | a | 1,2 |
| b | 1 | |
| 1,2 | a | 1,2,3 |
| b | 1 | |
| 1,2,3 | a | 1,2,3 |
| b | 1,4 | |
| 1,4 | a | 1,2 |
| b | 1 |
また、もともとの受理状態 4 を含むリストを新たな受理状態とします。
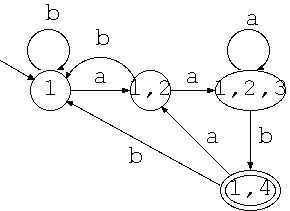
この決定性オートマトンを元に、入力文字列から.*aab と一致する回数を求め るプログラムを示します。
import java.io.*;
enum State {
S1, S12, S123, S14
}
class Rei {
private static int get(Reader r) throws IOException {
int c;
do{
c=r.read();
}while(c=='\n' || c=='\r');
return c;
}
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
int count=0;
State s=State.S1;
while((c=get(r))!=-1){
switch(s){
case S1:
if(c=='a'){ s=State.S12; }
else if(c=='b'){ s=State.S1; }
break;
case S12:
if(c=='a'){ s=State.S123; }
else if(c=='b'){ s=State.S1; }
break;
case S123:
if(c=='a'){ s=State.S123; }
else if(c=='b'){ s=State.S14; }
break;
case S14:
count ++;
if(c=='a'){ s=State.S12; }
else if(c=='b'){ s=State.S1; }
break;
}
}
if(s==State.S14){
count ++;
}
System.out.println(count);
}
}
次の文字列が含まれる回数を数えるプログラムを作りなさい。
なお、これも列挙型にメソッドを持たせると、次のようになります。
import java.io.*;
enum State {
S1 {
public State nextState(int c){
if(c=='a'){ return S12; }
if(c=='b'){ return S1; }
return ERROR; // アルファベットが a,b ならここに来ること
// はないが、必ずState 型の値を返す必要がある
}
public boolean isAccept(){
return false;
}
},
S12 {
public State nextState(int c){
if(c=='a'){ return S123; }
if(c=='b'){ return S1; }
return ERROR;
}
public boolean isAccept(){
return false;
}
},
S123 {
public State nextState(int c){
if(c=='a'){ return S123; }
if(c=='b'){ return S14; }
return ERROR;
}
public boolean isAccept(){
return false;
}
},
S14 {
public State nextState(int c){
if(c=='a'){ return S12; }
if(c=='b'){ return S1; }
return ERROR;
}
public boolean isAccept(){
return true;
}
},
ERROR {
public State nextState(int c){ // すべての状態に
return ERROR; // abstract メソッドを実装しな
} // ければならない
public boolean isAccept(){
return false;
}
};
abstract public State nextState(int c);
abstract public boolean isAccept();
}
class Rei {
private static int get(Reader r) throws IOException {
int c;
do{
c=r.read();
}while(c=='\n' || c=='\r');
return c;
}
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
int count=0;
State s=State.S1;
while((c=get(r))!=-1){
s = s.nextState(c);
if(s.isAccept()){
count++;
}
}
System.out.println(count);
}
}
ここでは受理状態の回数を数えるため、主ループ内で回数を数える処理を行っ ています。
前回の手法では、非決定性オートマトンから決定性オートマトンを構成してま した。そのため、遷移可能な状態なリスト間の関係を求めてました。 しかし、これを行うと、非決定性オートマトンの状態数を m とした時、 個のリスト間の関係を調べなければなりません。 これは、例えば正規表現を入力させるようなプログラムでは入力に対する効率 が非常に悪くなります。
ここでは、正規表現を文字列として与え、入力に何箇所マッチするかを効率良 く計算する方法を考えましょう。 文字列の長さを m とし、入力の長さを n とします。
駄目な方法は、正規表現に対応した非決定性オートマトンを作り、決定性オー トマトンに変換してから入力を一文字ずつ見ていく方法です。こうすると決定 性オートマトンへ変換する手間を考慮しなければならないので、必要な計算量 は となります。
そこで、決定性オートマトンを完全に作らずに入力を読むことを考えます。 そのためには正規表現や、非決定性オートマトンだけを使って入力を判断する 必要があります。 そこで、非決定性オートマトンに対して、非決定的な状態遷移をそのまま計算 することを考えます。 ある瞬間に遷移可能な状態は複数存在しますが、それは高々正規表現の長さ m 程度です。 そして、その遷移可能な状態のそれぞれについて、入力文字を与えると、次に 遷移可能な状態を計算することができます。 次に遷移可能な状態も高々 m 個なので、そのための手間は結局 で計算できます。 入力一文字に対して の手間がかかるので、全体では の手間がかかります。
正規表現を解釈するには、カッコの解釈などが必要なため、それ自体文 法によって解析しなければなりません。 そこで、ここでは簡単のために、正規表現の一部である文字列を入力と仮定し、 その文字列を何回含むかを計算するプログラムを作ります。
入力の仕様として、実行のさせ方が public static void main(String[] arg)
とした場合、 arg[0] が pattern で、 arg[1]
が string になります。
pattern を string にマッチさせていきますが、どこからマッチさせるかがポ イントになります。 プログラムの設計として、 string を一文字ずつ読み込み、そこで pattern がどれくらい検出できたかを調べます。 string を一文字ずつ読み込むのに、 java.io.StringReader を使用します (Reader 系を使用しておくと、あとでファイルなど別の入力に置き換えること が楽になります)。 一方、オブジェクト指向分析的にこの正規表現を処理するもの自体が一つのオ ブジェクトとして考えられます。 そこで、そのオブジェクトのクラス(Matcher と名づける) を作ります。 Matcher クラスはパターンにより初期化されます。 そして、一文字ずつの入力に対し受理状態に入った入ってないかを判定するメ ソッド match(int c) を持たせます。
import java.io.*;
class Matcher {
public Matcher(String pattern){...}
public boolean match(int c){...}
}
class Rei {
public static void main(String[] arg) throws IOException {
final Matcher m = new Matcher(arg[0]);
final Reader r = new StringReader(arg[1]);
int count=0;
int c;
while((c=r.read())!=-1){
if(m.match(c)){
count++;
}
}
System.out.println(count);
}
}
さて、それでは Matcher クラスを考えます。
アルゴリズムは、次の文字が来たとき、パターンのどこと照合するかを覚えて おくというものです。 そのため、整数で表した位置を無制限で保存できる LinkedList を使います。 一文字読む毎に、その LinkedList に保存されている位置を順に取り出します(*1)。 そして、その位置のパターンの文字と得られた文字を比較し、異なっていたら その保存していた位置を破棄します(*2)。 同一だった場合、最後まで読めていたら「マッチした」と言うことにします(*3)。 まだパターンが残っている場合は位置を一つ進めて保存します(*4)。
その他に、読み込んだ文字がパターンの 0 番目の文字に一致したら 1 番目と いう位置を新たに LinkedList に加えます(*5)。 なお、パターンが 1 文字だった場合は「マッチした」ことにします(*6)。
import java.util.*;
class Matcher {
final private String pattern;
final private LinkedList<Integer> pointer;
public Matcher(String pattern){
this.pattern = pattern;
pointer = new LinkedList<Integer>();
}
public boolean match(int c){
boolean result = false;
final ListIterator<Integer> i = pointer.listIterator();
while(i.hasNext()){ //*1
int j = i.next();
if(c==pattern.codePointAt(j)){
j++;
if(j==pattern.length()){
result=true; //*3
i.remove();
}else{
i.set(j); //*4
}
}else{
i.remove(); //*2
}
}
if(c==pattern.codePointAt(0)){
if(pattern.length()==1){
result=true; //*6
}else{
pointer.add(1); //*5
}
}
return result;
}
}
指定した文字列を含む行を表示するプログラムを作りなさい。
UNIX 系の OS では正規表現とマッチする行を表示するプログラム grep が用 意されています。 また、Windows には findstr コマンドが用意されてます。
文字列に対して正規表現やオートマトンにより部分列を抽出することを考えます。
正規表現において、通常抽出する部分を () (丸カッコ)で括って表現します。
例えば、自然数を取り出したいときは、
なお、受理する文字列は終了状態にたどり着けば一応得られることになります。 但し、上記の例のような自然数の表現の中に自然数が含まれるような状況の場 合、さらにルールが必要になります。 つまり、 12345 のような文字列の場合、「1」「2」「3」「4」「5」と全て分 割するのか、「1」「12」「123」「1234」「12345」「2」... と全ての場合を 出力するのか、それとも「12345」とするのか。 これはケースバイケースになりますが、通常は最長一致となる 「12345」を選択することが多いと思います。
最長一致した部分を取り出すには、まずその部分を示すオートマトンを作りま す。 基本的にはプログラムは初期状態から、そのパターンに入る先頭文字を読んだ らバッファへの記憶を開始します。そして、受理状態に入ったらバッファの内 容を書き出す準備をします。そのまま拒否状態に入らなければ解釈をどんどん 続けていきます。 そして、最終的に拒否状態になるまで入力を読み、その時点で直前の受理状態 に準備したバッファの内容を出力します。
繰り返し同一パターンで最長一致部分を出力しつづけるプログラムを作るには、 上記の拒否状態になった時点で初期状態に戻っている必要があります。 これを実現するために安易な方法として、一端拒否状態になったら、読み込ん だ文字を一文字入力に返してから初期状態に戻す手があります。 一方、拒否状態になる入力に対して ε 動作で初期状態に戻るような 動きを考えます(入力に応じて遷移しているので実際は ε 動作では ありません)。 これを便宜上 λ 動作として、非決定性のオートマトンとみなし、上記 と同様の分析で決定性のオートマトンを導く手もあります。
ここではテキストファイルから自然数を最長一致で取り出すオートマトンの分 析と、プログラム例を示します。
まず、はじめに自然数を受理するオートマトンを示します。
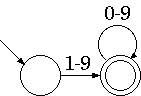
ここで、受理状態で入力 0-9 を受け取ると、そのまま受理状態に遷移します。 そして、これは初期状態で認識を開始する 1-9 を含んでます。 ここで、認識中に受理状態から拒否状態に移る入力を受け取ることを考えると、 その入力は 1-0 ではありません。 したがって、その入力では初期状態から認識が始まりません。 そのため、自然数を最長一致で読む場合、自然数と自然数の切れ目は必ず 1-9 以外の文字になります。 そのため、受理状態から決定的に抜けることができます。 つまり、非決定的な λ 動作をする のではなく、単にその他の文字として初期状態に戻せば良いことになります。
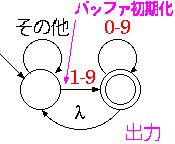
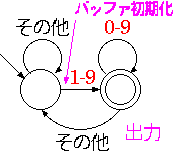
このオートマトンを実装して、入力から数を取り出すプログラムを示します。
import java.io.*;
enum State {
STATE1, STATE2
}
class Rei {
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
State s=State.STATE1;
final StringBuilder sb=null;
while((c=r.read())!=-1){
switch(s){
case STATE1:
if((c>='1')&&(c<='9')){
sb = new StringBuilder();
sb.append((char)c);
s=State.STATE2;
}else{
s=State.STATE1;
}
break;
case STATE2:
if((c>='0')&&(c<='9')){
sb.append((char)c);
s=State.STATE2;
}else{
System.out.println(sb.toString());
s=State.STATE1;
}
break;
}
}
if(s==State.STATE2){
System.out.println(sb.toString());
}
}
}
しかし、このプログラムでは得られた数を使うのが難しいです。 イテレータのように、呼び出すたびに順々に数を返すようなメソッ ドが実装されているようなオブジェクトがあると便利です。 そこで、 java.io.Reader オブジェクトを与えることにより、数を順に得るメ ソッドを実装した Parser クラスを作ります。
なお、毎回文字列を取り出すような関数を作るときには注意が必要です。 この数を取り出す場合もそうですが、EOF という文字列の最後を読んだとき、 取り出すべき最後の数が確定します。 そのため、 EOF が終わっても、すぐには終了できず、最後の数を返す必要が あります。 そして、その次の呼び出しで、初めて終了処理を行います。 そのため、読み込んだ値を保存しておき、返すべきものが無くなってから終了 処理を行います。
import java.io.*;
class Parser {
enum State {
STATE1, STATE2
}
private Reader reader;
private int lastChar;
private State s;
public Parser(Reader r)throws IOException{
reader = r;
lastChar=reader.read();
s=State.STATE1;
}
public String nextToken() throws IOException{
final StringBuilder sb = new StringBuilder();
while(true){
switch(s){
case STATE1:
if(lastChar==-1){
return null;
}
if((lastChar>='1')&&(lastChar<='9')){
sb.append((char)lastChar);
s=State.STATE2;
break;
}
s=State.STATE1;
break;
case STATE2:
if((lastChar>='0')&&(lastChar<='9')){
sb.append((char)lastChar);
s=State.STATE2;
break;
}
s=State.STATE1;
return sb.toString();
}
lastChar = reader.read();
}
}
}
class Rei {
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
final Parser p = new Parser(r);
String str;
while((str=p.nextToken())!=null){
System.out.println(str);
}
}
}
なお、このような仕組みは java.util.regex ライブラリに既に用意されてい ます。 これまで説明してきたプログラミングテクニックは重要ですが、実際に文字列 処理を行う場合は下記のように java.util.regex ライブラリを使った方が良 いでしょう。
import java.util.*;
import java.util.regex.*;
import java.io.*;
class Rei2 {
public static void main(String arg[]) throws IOException {
final BufferedReader br = new BufferedReader(
new InputStreamReader(System.in));
String buf;
final Pattern p = Pattern.compile("[1-9][0-9]*");
Matcher m;
while((buf=br.readLine())!=null){
m= p.matcher(buf);
while(m.find()){
System.out.println(m.group());
}
}
}
}
テキストファイルから整数、つまり、-123 や 0 や 4567 というような表現を 最長一致で取り出すプログラムを作りなさい。
与えられた ( と ) の記号列のうち、ちゃんとカッコが閉じている記号列だけ を集めた集合をカッコ言語と言います。 「()」、「((()))」「(())()」などがカッコ言語の元になります。 ここでは、正規表現ではカッコ言語を表現できないことを示します。
正規表現が決定性オートマトンと等価であるという性質を使います。 つまり、カッコ言語を表現する決定性オートマトン M が存在することを仮定して、 矛盾を導きます。
決定性オートマトン M の状態数が n であるとする。 さて、ここで ((...()...)) と開きカッコが n+1 個続いた後、閉じカッコが n+1 個続くカッコの列 s を考えます。 仮定によりこれは M により受理されます。 ここで、開きカッコに注目します。 s が M に入力されると、 状態数は高々 n しかありません。 そのため、状態遷移において、ある状態は必ず 2 回以上現 れます。 その状態を q とします。 そして、 q が出現するのが i 番目と j 番目の開きカッコを 入力したあとであるとします。
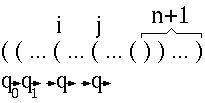
さて、i 番目の入力の後に j+1 番目の入力を与えることを考えます。 つまり、開きカッコが n+1-(j-i) 個と閉じカッコが n+1 個ある入力を考えま す。
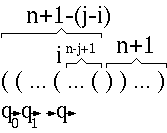
この入力では開きカッコに比べて閉じカッコが多すぎるので、拒否しなければ なりません。 しかし、 i 番目と j 番目で同じ状態 q に入り、状態 q には n+1 個の開き カッコと閉じカッコが与えられたときと同様に j+1 番目の入力が与えられま す。 そのため、この開きカッコが少ない入力でも受理しなければなりません。 これは M がカッコ言語を受理するという仮定と矛盾します。 よって、カッコ言語は正規表現で表せません。

オートマトンに対して記憶装置としてテープを接続したものをチュー リング機械と言います。 決定性のチューリング機械で計算できるものと、現在のコンピュータで計算でき るものは可能か不可能かに限っては等価であることが知られています。
入力の長さに対して、決定性のチューリング機械で計算ステップ数が多項式で 表せる問題のクラスを P と言います。 同様に、非決定性のチューリング機械で多項式ステップ数で計算できる問題の クラスを NPと言います。 これらが等しいかどうかは計算機科学上で重要な未解決問題で P=NP 問 題 と言います。
NP 問題に含まれるものに素因数分解、地図の三色彩色可能性問題(平面の地図 は必ず四色で塗れることはわかっています)、巡回セールスマン問題(都市間の 交通費がわかっている時全都市を予算内で回れるかどうかを決める問題)など があります。
例3-3 のプログラムにおいて enum の各状態にメソッドを与えたプログラムを 示します。 enum のメソッドでは static を指定しませんが、内部的には static のよう で、メンバ変数を使用したい場合は static の指定をします。
import java.io.*;
enum State {
STATE1 {
public State nextState(int c){
if((c>='1')&&(c<='9')){
sb = new StringBuilder();
sb.append((char)c);
token = false;
return STATE2;
}
token = false;
return STATE1;
}
},
STATE2 {
public State nextState(int c){
if((c>='0')&&(c<='9')){
sb.append((char)c);
token = false;
return STATE2;
}
token = true;
return STATE1;
}
};
private static StringBuilder sb; // メンバ変数は static にする。
public String getToken(){
return sb.toString();
}
private static boolean token=false;
abstract public State nextState(int c);
public boolean hasToken(){
return token;
}
}
class Rei {
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
int c;
State s=State.STATE1;
StringBuilder sb=null;
while((c=r.read())!=-1){
s=s.nextState(c);
if(s.hasToken()){
System.out.println(s.getToken());
}
}
if(s==State.STATE2){
System.out.println(s.getToken());
}
}
}
次に、これの Parser バージョンを示します。
import java.io.*;
class Parser {
private static StringBuilder sb; // 内部の enum のメソッドは static
private static boolean hasToken=false;
enum State {
EOF { // 終了状態を示す状態を追加
protected State nextState(int c){ // 必要なくても abstract
// 宣言したメソッドに対しては
// すべての要素でメソッドを実装する
return EOF;
}
},
STATE1 {
protected State nextState(int c){
if(c==-1){
return EOF;
}
if((c>='1')&&(c<='9')){
sb = new StringBuilder();
sb.append((char)c);
hasToken = false;
return STATE2;
}
hasToken = false;
return STATE1;
}
},
STATE2 {
protected State nextState(int c){
if((c>='0')&&(c<='9')){
sb.append((char)c);
hasToken = false;
return STATE2;
}
hasToken = true;
return STATE1;
}
};
abstract protected State nextState(int c);
}
final private Reader reader;
private int lastChar;
public Parser(Reader r){
reader = r;
lastChar=reader.read();
}
public String nextToken() throws IOException{
State s=State.STATE1;
while(true){
s = s.nextState(lastChar);
if(s==State.EOF){
return null;
}
if(hasToken){
return sb.toString();
}
lastChar=reader.read();
}
}
}
class Rei {
public static void main(String[] arg)throws IOException{
final Reader r = new InputStreamReader(System.in);
final Parser p = new Parser(r);
String str;
while((str=p.nextToken())!=null){
System.out.println(str);
}
}
}