このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
はじめに、入力データの意味や内容を解析するために、文法理論を学びます。 参考書を選ぶ時は、「コンパイラ論」のようなものが参考になります。
コンピュータで文字(記号)列を解釈するには、その文字列がどのようなルール で作られているかを知る必要があります。 文字列のルールを文法と言います。 そして、ルールに適合する文字列すべての集合を言語と言います。 なお、ルールから適合する文字列を導くことを生成すると言います。 特定の文法を記号 G で表す時、その文法で生成される言語を L(G) と書くこ とがあります。 なお、記号の全体集合をアルファベット と言います。 しばしばアルファベットはΣで表されます。 そして、そのアルファベットΣから作られる記号列全体の集合を で表します。 なお長さが0の記号列(空列)をεで表します。
正規表現を次のように定義します。
正規表現は一つの文法になりうるので、正規表現で一つの言語を定義すること ができます。
メモリーが有限個しか使えないコンピュータが計算できる言語は正規表現だけ であることが知られています。 このように正規表現はプログラムと非常に密接な関係にありますので、さまざ まなところで使用されています。 例えば、 MS-DOS プロンプトやコマンドプロンプトなどでも、ファイル名を指示 する時、不完全ながらも正規表現が使えます。
但し、これは ab, abab, ababab, ... などの文字列の繰り返しの表現を指定できな いので、完全な意味での正規表現ではありません。 しかし、一応複数のファイル名などを一つの文法で表すことが できます。
コマンドプロンプトまたは MS-DOS プロンプトで c:\windows または
c:\winnt ディレクトリの中のファイルのうち、次の条件に当てはまるファイ
ル名を dir コマンドを使って表示しなさい。
但し、 Windows や MS-DOS はファイル名を二つの文字列を.(ピリオド)でつな
がった形で表しています。
後ろの文字列を拡張子と言います。
例えば「拡張子が txt のファイル名」は
Java ではバージョン 1.4 から java.util.regex パッケージが追加され、次 のような構文で正規表現が使えるようになりました。
java.util.regex.Pattern p = java.util.regex.Pattern.compile("a*b");
java.util.regex.Matcher m = p.matcher("aaaaab");
boolean b = m.matches();
また簡易版として、 java.lang.String クラスに matches メソッドが追加さ れ、次の表記も可能になりました。
boolean b = "aaaaab".matches("a*b");
以下は Java での正規表現を表し方の例です(詳しくは言語のリファレンス を御覧下さい)。
\p{名前} は POSIX character classes を指定するのに使います。
\p{Lower} は小文字[a-z]、\p{Upper}は大文字
[A-Z]、\p{Alpha} はアルファベット[\p{Lower}\p{Upper}]、
\p{Digit}は数字[0-9]、\p{Alnum}は英数字
[\p{Alpha}\p{Digit}]、\p{Space}は空白[ \t\n\x0B\f\r] を表
します。
以下のアプレットを使って、ランダムな 1000 個の文字列のうち、次の文字列 がいくつ出て来るか調べなさい。但し、文字列の長さは 5 とします。
(注)このプログラムはJavascriptで作られているので、Javaと表現方法 が異なる場合があります
次の Java の正規表現が受理する言語(文字列の集合)を求めなさい。
次の文字列を表す正規表現を示しなさい。
例えば、単語は、英字で始まって、英字または数字が連続するものですが、そ
れは [A-Za-z][A-Za-z0-9]* と書くことができます。あるいは
Java ではもっと簡単に \p{Alpha}\p{Alnum}*と書くこともで
きます。
これを使うと次のようなプログラムが書けます。
import java.util.regex.*;
class Sample {
public static void main(String[] args){
final String sample="This is a pen.";
final Pattern p = Pattern.compile("\\p{Alpha}\\p{Alnum}*");
final Matcher m = p.matcher(sample);
while(m.find()){
System.out.println(m.group());
}
}
}
String input="-10+30-20";
ここまでは正規表現を解釈するツールを利用してきました。 これからは、原理を学ぶために正規表現をプログラムに変換する手法を学びます。 単純な正規表現ならわざわざツールに頼らなくとも簡単なプログラムで解釈で きます。
始めにオートマトンについて学びます。 オートマトンとは次のような有向グラフです。
文字列に対して、開始ノードから一文字ずつたどって終了ノードにたどり着け た時、オートマトンはその文字列を受理すると言います。 一方、辺がなかったり、文字列が終った時に終了ノードではなかった時 拒否すると言います。 オートマトンにより、受理する文字列の集合が決定できます。受理する文字列 の集合をそのオートマトンが受理する言語と言います。
各ノードから出る辺に割り当てられている文字がすべて異なるオートマトンを 決定性オートマトンと言います。 このオートマトンは状態遷移図とも呼びます。 決定性オートマトンは入力により流れが分岐するだけですので、簡単にプログ ラムに変換できます。
一方、各ノードから出る辺に割り当てられている文字にダブりがあったり、 ε(空文字)が割り当てられているオートマトンを非決定性オート マトン と言います。 これから、この講義で非決定性オートマトンの受理する言語と正規文法で定められる言語が 一致することを示します。 具体的には正規文法から非決定 性オートマトンへの変換の仕方、次回の講義では非決定性オートマトンから決 定性オートマトンへの変換法を示します。 (非決定性オートマトンから正規文法への変換方法は省略します)
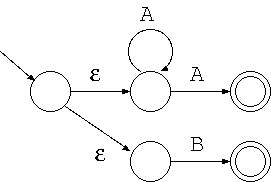
帰納法により証明します。
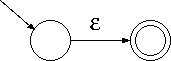
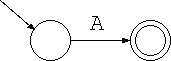
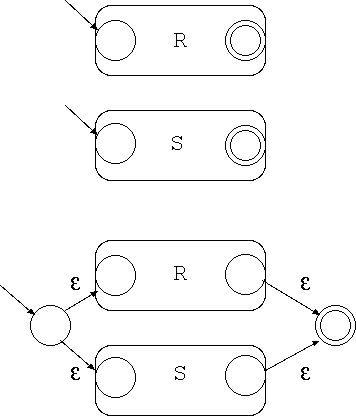
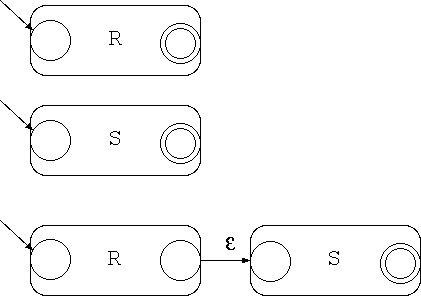
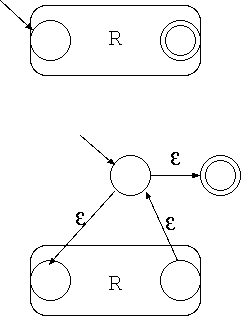
(証明終)
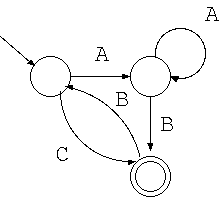
正規表現 a は次のような非決定性オートマトンになります。
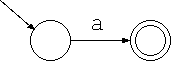
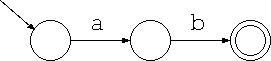
正規表現 ab は次のような非決定性オートマトンになります。
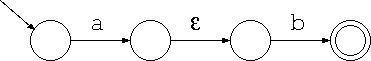
但し、このオートマトンでεを考える必要は無いので、省略できます。 このように状態数の少ない等価なオートマトンを導くことを 簡単化と言います。
正規表現 (ab|ac) は次のような非決定性オートマトンになります。
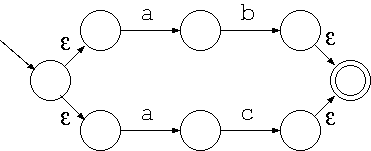
但し、これも最初の入力はどちらも a なので εを考える必要はありません。 また、次の入力 b, c でともに受理状態に入ればいいので、こちらも省略できます。 そのため次のように簡単化できます。
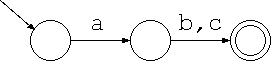
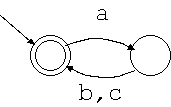
正規表現 (ab|ac)* は次のような非決定性オートマトンになります。
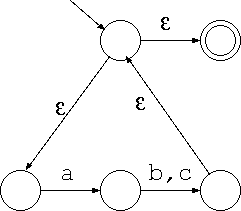
これもこのように簡単化できます。
次の正規表現を受理する非決定性オートマトンを作りなさい。