このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
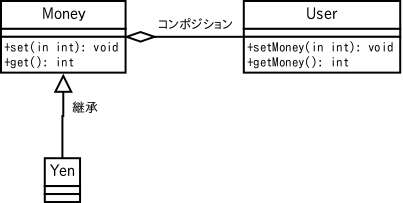
オブジェクトクラスを作成した後、その機能を拡張するような利用法を考えます。 例えば、お金を扱う Money というクラスがあったとします。 Money には金額を記憶する set メソッドと、 金額を取り出 す get メソッドがあるとします。
class Money {
public void set(int value){ ... }
public int get(){...}
}
さて、顧客クラス User の購入金額を管理するためにこの Money クラスを利用したいとします。 そのために、この User クラスのオブジェクトは購入金額を記憶するための setMoney メソッドと、購入金額を取り出す getMoney メソッドを使用するこ ととします。 このような場合、次のように、インスタンス変数として Money の型の変数を 用意し、それぞれのメソッドに対して、 Money の set, get を割り当てます。
class User {
private Money kounyuu;
public User(){
kounyuu = new Money();
}
public void setMoney(int value){
kounyuu.set(value);
}
public int getMoney(){
return kounyuu.get();
}
...
}
一方、円レートで金額を記憶、取り出しができるクラス Yen があったとしま す。 これは Money クラスとほとんど同じようなものなので、 Money クラスをほと んどそのまま利用できたら便利です。 そのため、上記のようなオブジェクトを保持してメソッドを付加する方法では 無く、継承を使います。すると、 Money のメソッドすべてを受け継ぐこ とができ、 Money と同じ扱いができます。
class Yen extends Money {
...
}
さて、 User も Yen も、ともに Money クラスを利用しましたが、この 「利用」の違いはなんでしょうか? これは、 Money クラスと User クラスあるいは Yen クラスとの関係の違いに よるものです。 User にとっては Money は所有する関係ですが、 Yen にとっては Money は所 有関係ではなく、 Yen は Money そのものです。 つまり、 「A User has (a) Money」「(A) Yen is (a) Money」と書ける性質から(Money が不加算名詞なのでこの場合は表現がおかしいですが)、この関係をそれぞれ 「has-a 関係」、「is-a 関係」と呼びます。
ふたつのオブジェクトクラス A, B が「is-a 関係」であれば継承を使います。 つまり「Yen は Money である」のであれば Yen は Money のサブクラスにな ります。 一方、オブジェクトクラス A, B が「has-a 関係」であれば、インスタンス変 数を作り、そこに B のオブジェクトを入れて使用します。 この、クラスの中にインスタンス変数を作り、その変数に他のオブジェクトを 入れて使用することをコンポジションと言います。 User は Money を持っているので、コンポジションを使って Money クラスを 利用します。
これらの関係を表すため、 UML ではコンポジション(UML 用語では Aggregation) にはヒシ型の矢印、継承には三角形の矢印を使って表します。
この継承やコンポジションの区別は重要ですが、取り違えても誤りではありま せん。 うまく選択できると、利便性が上がる性質があるということです。
例えば、人物を表すとき、名前と誕生日を人物の情報に含めたいとします。 人物は名前や誕生日ではありませんから、明らかに has-a 関係です。 そのため、コンポジションを使って下記のようなクラスを作ります。
import java.util.Date;
class Person {
private String name;
private Date birthDay;
public Person(){}
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setBirthDay(Date birthDay){
this.birthDay = birthDay;
}
public Date getBirthDay(){
return birthDay;
}
}
例6-1 の Person クラスを使って顧客のオブジェクトクラス Customer を作り ます。 顧客は名前、誕生日など Person と同じ項目の他、顧客コード(id)を持つもの とします。 すると、顧客は人物なので Person クラスとは is-a 関係になります。 一方、顧客は顧客コードでは無いので、顧客コードはコンポジションとして内 部に持ちます。 したがって顧客クラスは次のようになります。
class Customer extends Person {
private String id;
public Customer(){
super(); // サブクラスを作るときはコンストラクタで super を呼ぶ
}
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
これだけで Person 同様に setName, setBirthDay などの Person のメソッド も使用できるようになります。
なお、コンポジションを行う場合、 外部からオブジェクトを与える場合と、単に外部からメソッドを呼ぶだけの二 通りの場合があります。 外部から単にメソッドを呼ぶだけの場合は、メソッドが呼ばれる前にコンスト ラクタなどを呼び出して内蔵するオブジェクトをあらかじめ生成しておく必要 があります。
前回、 CRC カード分析などで、オブジェクトクラスがプログラムの仕様書と 密接な関係で作られることを学びました。 これはつまり、クラス自体が仕様書とよく関連づけられるということです。 そこで、クラスを作るときに同時に簡易な方法でドキュメントが作成できると 便利です。 Java では JavaDoc という仕組があり、各クラスやメソッドの宣言を行う前に 特別なコメントを書いておくと、 javadoc コマンドなどで自動的にクラスに 関するドキュメントが作られます。
例えば、前回の演習問題にあった、組合せ数を求めるようなクラスやメソッドを定 義してみましょう。
javadoc は public な class (パッケージ外から使うクラス)しかド キュメント化しないので、下記の例も public class でクラスを宣言していま す。 public class ではクラス名とファイル名が一致している必要があります。 つまり、下記の例ではファイル名は Type2.java でなければなりません。
/**
* 組合せの数を求める実装例 2
* @author 坂本直志
* @version 1.0
*/
public class Type2 {
/**
* 組合せの数を計算する静的メソッド
* @param n 選ばれるものの総数
*@param m 選ぶ数
*@return nCm の値を返します
*/
public static int combination(int n, int m){
if(n==0) return 1;
if(n==m) return 1;
return combination(n-1,m)+combination(n-1,m-1);
}
}
これを javadoc Type2.java とするとドキュメント が作られます。
JavaDoc 中で使用可能なタグは、(なぜか)マニュアルの「JavaDoc テクノロジ」 の「ツール」のドキュメントに書かれています。
さて、オブジェクトのコピーを行うことを考えます。 java.lang.Object クラスには protected なメソッドとして clone がありま す。 これを使用するとオブジェクトのコピーが作られます。 但し、マニュアルには「シャローコピー(浅いコピー)が作られ、 ディープコピー(深いコピー)は作られません」と書かれています。 さて、このシャローコピー、ディープコピーとはなんでしょうか?
そこで、オブジェクトのコピーを考える前に、まず配列のコピーについて考え ましょう。 配列は clone を public に使用できます。
二次元配列に対して clone がどのような動きをするのか以下のプログラムで 見てみましょう。
class Rei {
/**
* int の二次元配列を表示する関数
* @param 二次元配列
*/
private static void showArray(int[][] a){
for(int[] b: a){
for(int c : b){
System.out.print(c+" ");
}
System.out.println();
}
horizon();
}
/**
* 水平線を表示する関数
*/
private static void horizon(){
System.out.println("--------");
}
private static int counter=0;
/**
* 自動的に加算する番号を表示する関数
*/
private static void showCounter(){
System.out.println(++counter+".");
horizon();
}
public static void main(String[] arg){
showCounter();
final int[][] array1 = {{1,2,3},{4,5,6},{7,8,9}};
final int[][] array2 = array1.clone();
showArray(array1);
showArray(array2);
showCounter();
array1[2]=new int[]{12,13,14}; // final では配列の
// 中身を固定できない
showArray(array1);
showArray(array2);
showCounter();
array1[1][0] = 10;
array2[0][1] = 11;
showArray(array1);
showArray(array2);
}
}
ここで意図しているのは次のような結果です。
array2 = array1.clone();
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
array1[2]=new int[]{12,13,14};
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 12 | 13 | 14 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
array1[1][0] = 10;
array2[0][1] = 11;
| 1 | 2 | 3 |
| 10 | 5 | 6 |
| 12 | 13 | 14 |
| 1 | 11 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
しかし、結果は次のようになりました。
array2 = array1.clone();
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
array1[2]=new int[]{12,13,14};
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 12 | 13 | 14 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
array1[1][0] = 10;
array2[0][1] = 11;
| 1 | 11 | 3 |
| 10 | 5 | 6 |
| 12 | 13 | 14 |
| 1 | 11 | 3 |
| 10 | 5 | 6 |
| 7 | 8 | 9 |
2 までの操作は意図しているように実現されていますが、 3 の操作がおかしいで す。 2 と 3 を分析するとどうやら、 array1 と array2 は異なるオブジェクトを 指していますが、 array1[0] と array2[0] や array1[1] と array2[1] は同 じものを指しているようです。 図にすると次のようになります。
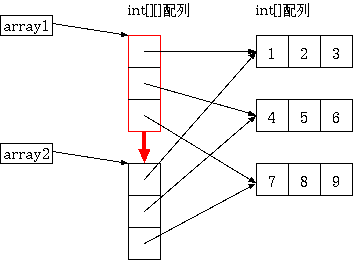
コピーの状態
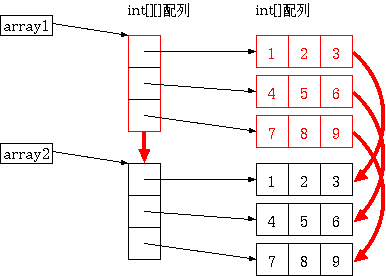
理想形
これはつまり、 array1 が直接指しているオブジェクトのみが array2 にコピー される一方で、 array1 の int[][] のオブジェクトが指している、それぞ れ int[] 型の {1,2,3}、{4,5,6}、{7,8,9} はコピーされなかったことを意味 します。 シャローコピーとはこのように変数が直接指しているオブジェクトのみをコピー することを言います。 それに対して、ディープコピーは元のオブジェクトの内部のオブジェクトまで 全てコピーすることを意味します。
そこで、 clone メソッドの代わりにディープコピーをする関数を作ります。 このようにすると上記の理想形の通りの結果が得られます。
private static int[][] deepCopy(int[][] a){
final int[][] result = a.clone();
for(int i = 0; i < result.length; i++){
result[i] = result[i].clone(); // 参照先を複製する
}
return result;
}
さて、コピーにはシャローコピーとディープコピーのふたつが有ることが分か りました。 次に、オブジェクトにおいてコピーを作る方法を考えてみましょう。
前にも述べましたが、 java.lang.Object の clone メソッドは protected な ので、通常のオブジェクトを作成した場合、オブジェクトの定義内では使用で きても、そのオブジェクトを使用する別のクラスからは clone メソッドを呼 ぶことができません。 そこで、外部から clone をさせるには、 public な clone をするメソッドを 作る必要があります。
次のプログラムは clone を単純に実装したものです。 java.lang.Cloneable(綴りがわざとまちがっていること注意)を implement し て、 clone メソッドをオーバライドします。 従来は clone が返すオブジェクトの型は java.lang.Object でしたが、 java 5 からは属するクラスの型も使えるようになりました。 clone メソッドでは super.clone() の値を返します。 但し、java.lang.Object の clone は Object 型を返すので、ダウンキャスト をする必要があります。 なお、 clone メソッドは java.lang.CloneNotSupportedException 例外を投 げるように宣言します。
class Item implements Cloneable {
private int value;
/** デフォルトコンストラクタ
*/
public Item(){}
/** セッター
*@param 整数値
*/
public void set(int value){
this.value = value;
}
/** 文字列へ変換
*/
@Override public String toString(){
return String.valueOf(value);
}
/** オブジェクトのコピーを作る
*@throws CloneNotSupportedException
*/
@Override public Item clone() throws CloneNotSupportedException{
return (Item) super.clone();
}
}
class Rei {
public static void main(String[] arg)throws CloneNotSupportedException{
final Item item1 = new Item();
item1.set(1);
final Item item2 = item1;
final Item item3 = item1.clone();
System.out.println(item1+" "+item2+" "+item3);
item2.set(2);
item3.set(3);
System.out.println(item1+" "+item2+" "+item3);
}
}
このようにオブジェクトのコピーを作るメソッドを作成するには clone を使 う方法がスタンダードな方法です。 一方、コピーコンストラクタという方法もあります。 これはクラスのインスタンスオブジェクトをコンストラクタに与えて、与えら れたオブジェクトと同じになるようにコピーをするものです。上記の例でコピー コンストラクタを作ると次のようになります。
class Item {
private int value;
/** デフォルトコンストラクタ
*/
public Item(){}
/** コピーコンストラクタ
*@param コピーされるオブジェクト
*/
public Item(Item item){
this.value = item.value;
}
/** セッター
*@param 整数値
*/
public void set(int value){
this.value = value;
}
/** 文字列へ変換
*/
@Override public String toString(){
return String.valueOf(value);
}
}
class Rei {
public static void main(String[] arg){
final Item item1 = new Item();
item1.set(1);
final Item item2 = item1;
final Item item3 = new Item(item1);
System.out.println(item1+" "+item2+" "+item3);
item2.set(2);
item3.set(3);
System.out.println(item1+" "+item2+" "+item3);
}
}
clone はコンストラクタを呼びませんので、コンストラクタが介入しなければ ならないような処理を行うことができません。またサブクラスでも引き継いで しまいますので、サブクラスでシングルトンデザインパターンを使っていても オブジェクトをコピーできてしまうことがあります。 サブクラスでは clone メソッドを protected 宣言とかできませんので、親ク ラスで clone を実装する時は子クラスのことまで考える必要があります。 一方、コピーコンストラクタの引数にサブクラスのオブジェクトを与えることができ てしまいますが、そうなったときの動作が常に正しくなる保証はありません。
class A implements Cloneable {
private int num;
public A(){num=1;}
public A(A obj){
this.num = obj.num;
}
@Override public String toString(){
return "A: "+String.valueOf(num);
}
@Override public A clone() throws CloneNotSupportedException {
return (A) super.clone();
}
}
class B extends A {
private int num;
public B(){
super();
num = 2;
}
@Override public String toString(){
return "B: "+String.valueOf(num);
}
}
class Rei {
public static void main(String[] arg) throws CloneNotSupportedException {
final B b = new B();
System.out.println(b);
final A a1 = new A(b); // サブクラスのオブジェクトを指定できるが
System.out.println(a1); //サブクラスまでコピーできない
final A a2 = b.clone(); // 親クラスの clone だが
System.out.println(a2); // サブクラスまでコピーできる
}
}
なお、 Java のクラスライブラリの中で今まで紹介したクラスはどのようにコ ピーするようになっているかをまとめると、下記のようになっています。
| クラス | コピー方法 |
|---|---|
| java.lang.String | コピーコンストラクタ |
| java.lang.StringBuilder | なし(String 経由) |
| java.lang.Integer などのラッパクラス | なし(基本型経由) |
| java.io. 関係 | なし |
| java.util.ArrayList, LinkedList, HashSet, TreeSet | clone とコピーコンストラクタ両方 |
| java.util.HashMap, TreeMap | clone とコピーコンストラク タ両方 |
| java.util.Map.Entry | なし |
| java.util.Date | clone |
このようにコピーのできないクラスもあり、またコピーも必ず clone を使う のではなく、コピーコンストラクタのみというクラスもあります。
なお、 java.util.ArrayList などでは clone とコピーコンストラクタで働き が異なります。 ArrayList などは保存可能な初期サイズとして initialCapacity を指定できます。 さて、ここで例えば、 initialCapacity として 10000 を指定した ArrayList のインスタンスを作ったとします。 そして、 5000 個ほど要素を追加した状況を考えます。 ここで、clone を使うと、現状の initialCapacity を維持したまま要素をコ ピーします。 一方で、コピーコンストラクタを使うと、与えた 5000 個の要素に関して最適 なサイズの ArrayList が作られ、要素の参照がコピーされます。 つまり、 clone はオブジェクトの状態そのものをコピーしますが、コピーコ ンストラクタは新たなインスタンスを初期化して作る違いがここで生じます。
次にオブジェクトの比較について考えます。 同一メモリアドレス上にある、つまり、まさに参照先が同じかどうかを判定するには == を使用します。
しかし、文字列など、異なるメモリ上にあっても 内容が等しければ等しいと判断したいときがあります。 そのため java.lang.Object には equals というメソッドがあります。 このメソッドを各オブジェクトクラスの性質に応じてオーバライドして使用します。 equals を実装する際もコピーと同様に浅く比較するか、深く比較するかを検 討する必要があります。 なお、配列では java.util.Arrays に静的なメソッドとして equals と deepEquals が実装されています。
equals は数学でいう同値関係を満たす必要があります。つまり次 の三条件を満たさなければなりません。
null でない Object a,b,c に対しては、次を満たします。
a.equals(a)は truea.equals(b) と b.equals(a) は一致する
a.equals(b) と b.equals(c) がともに true で
あるなら、
a.equals(c) も true
この上、プログラミング的な制約として、オブジェクトが変化しない限りは何
度 equal を呼んでも結果が変化しないという整合性(初回だけ true で 2 回
目以降は false というのはダメ)と、 x.equals(null) は常に
false でなければならないという条件が付加されてます。
以上挙げた条件を実際に満たすことはそれほど厳しいことではないので、 いろいろな条件の equals を考えることができます。 例えば、「ある条件が成立する同一グループ」は大抵この性質を持っています。 つまり、例えば数を比較する場合、「値が完全に等しい」という条件の他に、 「3 で割った余りが等しい整数」なども上記の条件を満たします。 但し、 equals の字面は「等しい」を意味しますので、等しさからあまり直感 的に外れた定義をすると、プログラムが作りにくくなったり読みづらくなった りしますので、注意が必要です。
オンラインショッピングなどで顧客データを扱う際、通常顧客の ID で全て識 別します。 そのため、 equals の実装としてふさわしいのは次のように顧客の ID の比較 になります。
class Customer {
private String id;
...
/**
* 顧客の等価性を返します
* @param 顧客オブジェクト
* @return 同一の顧客かどうか
*/
public boolean equals(Customer customer){
return this.id.equals(customer.id);
}
}
なお、java.lang.Object における equals の引数は java.lang.Object なの で、この equals は Override にはなりません。 厳密に java.lang.Object の equals 関数を Override するためには、引数を Object 型にしなければなりません。 引数を Object に許すと、引数に対してそのまま Customer のメソッドを適用 できなくなります。つまり、キャストする必要があります。
/*
問題あり
*/
class Customer {
private String id;
...
@Override
public boolean equals(Object o){
Customer customer = (Customer) o;
return this.id.equals(customer.id);
}
}
ただし、このままでは equals の引数に null が与えられた場合や Customer クラスとは異なるオブジェクトが与えられた時に false が返りません。 さて、 Eclipse にはこの equals を自動生成する機能があります。 Customer に関して Eclipse に生成させると、次のようなプログラムを生成し ます。
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
final Customer other = (Customer) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
return true;
}
このようにかなり複雑な条件式になります。 このうち、最初の条件は単なる高速化のためですが、それ以降は、引数 obj とインスタンス変数 id に関して次のような条件を考えています。
なお、 getClass を用いる代わりに
instanceof 演算子を使うと、
null のチェックとクラスのチェックが同時にできます。
これを用いて Eclipse の記述をより短くすると次のようになります。
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Customer)) return false;
final Customer other = (Customer) obj;
if (id == null) return other.id==null;
return id.equals(other.id);
}
最初の if 文以外はガード文になっていて、そこで return しないと、次のス テップで必ずランタイムエラーが出ることに注意してください。 つまり、obj が Customer クラスのインスタンスで無い限りキャストできませ んし、id が null では equals メソッドを呼べないということです。
さて、等しいという条件として別の条件を考えてみましょう。 例えば、顧客 ID は異なっていても、名前と誕生日とお届先が一致して いるような顧客は本当に異なっているのでしょうか? コンピュータは条件さえそろえられれば、大量の顧客リストに関して、同一人 物の可能性のあるような顧客 ID リストなどを簡単に作ることができます。 誕生日自体は個人を特定しませんが、「異なっていれば別人」という情報を持っ ています。 電子マネーの ID や、レシート番号など、直接は個人情報にあたらないもので も大量に入手して処理することで個人を特定できることがあります。 このような情報処理を紐付けと呼びます。 個人情報保護が立法化され、社会的に個人情報の取扱いに注意が払われるよう になりました。 一方で、コンピュータの情報処理により、単独で は無意味な情報が個人の特定に大きく関与するようになりました。 そのため、法的には個人情報に当たらない情報でも、複数そろうと個人を特定で きてしまうこともあります。 そのため、 データベースなどを作る際には、情報を取り扱う責任や障害時の被害の軽減な ども考え、「責任の明確化」や「不必要な情報を採取しない」などの対応を考 える必要があります。
さて、話がそれました。
再び、「等しさ」の話に戻します。
java.lang.Object の equals の説明には
hashCode の実装をするように書かれています。
この hashCode(ハッシュ値) というのは各オブジェクトから作成
する長さの決まった値です。
Java では int 型、つまり 32bit になります。
このハッシュ値は equals の性質を一部受け継いでいます。
つまり、Object a,b に対して、 a.equals(b) が true である
なら、 a.hashCode() == b.hashCode() も成り立たなければな
らないということです。
これは a.equals(b) が false である場合には、何も規定して
ません。
対偶を考えると、a.hashCode() と b.hashCode()
が異なる場合は必ず a.equals(b) は false になるということ
です。
これは先ほどお話した誕生日がもつ条件と同じです。
「同一人物であれば誕生日が等しい」ということは、「誕生日が異なれば同一
人物では無い」ということです。
このようにハッシュ値というのはオブジェクトを表す一部の情報になります。
そして、equals は自由に設定できるという説明をしましたが、その場合、そ
の equals に連動したハッシュ値、つまり equals が true になるようなオブ
ジェクトに対しては常にハッシュ値が等しくなるようにする必要があります。
例6-7 では顧客の等価条件を顧客の ID と定めましたので、 hashCode は顧客 ID のハッシュ値を返すようにします。
class Customer {
private String id;
...
/**
* 顧客の等価性を返します
* @param 顧客オブジェクト
* @return 同一の顧客かどうか
*/
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Customer)) return false;
final Customer other = (Customer) obj;
if (id == null) return other.id==null;
return id.equals(other.id);
}
/**
* 顧客のハッシュ値を返します。
* これは顧客ID のハッシュ値と等しいです。
* @return ハッシュ値
*/
@Override public int hashCode(){
return id.hashCode();
}
}
なお、例えば、名前と生年月日が等しい時に equals が true を返すという場 合、どのように hashCode を返せば良いでしょうか? 複数のデータを持つオブジェクトの代表格として文字列型 java.lang.String があります。 このオブジェクトの hashCode はマニュアルによると次のように計算されます。
このように、複数のデータに対してハッシュコードを計算するには、 直前の値 x とデータ値 y に対して 31*x + y という値を与えています。
そのほかの与え方として、 java.lang.Long (64 bit の整数)では、上位 32 bit と下位 32 bit の排他的論理和を取っています。 排他的論理和は一方が 1 bit 異なれば、値になります。しかし、二つの同じ 値に対して排他的論理和をとると 0 になってしまうという性質もあります。 64bit の整数に対して、上位と下位が一致してしまうというのはあまり考えら れない状況ですが、文字列に関しては 1 文字目と 2 文字目が一致することは 十分考えられます。 したがって、複数のオブジェクトのハッシュコードの算出方法は少なくとも次 の二通りが使われています。
| オブジェクトの性質 | 演算 | 代表的な例 |
|---|---|---|
| 二つが一致する可能性が低い | 排他的論理和 x^y | java.lang.Long, java.lang.Double |
| その他 | 31*x + y | java.lang.String など |
異なる要素に対してなるべく異なる hashCode を用意すると、hashCode を使 うようなアプリケーションで検索などが高速になります。
なお、 Eclipse ではこのようなルールに基づいて equals と hashCode を自 動的に生成します。
なぜ 31 という特定の値を使うのかですが、 ひとつは 2 の 5 乗 - 1 という計算のしやすい値であることです。 もうひとつは以下の通りです。
まず、 31 の代わりに変数 x を用いて 二つの文字列 s[0,...,n-1] と t[0,...,n-1] に関して hashCode を求めると 次のようになります。
但し、これは高々 32 bit の演算なので、 で割った余りを考えることになります。 これが 一致する可能性を考えます。そこで、これに対して辺々引くと次のようになります。
hashCode がなるべく重ならないようにするには、 この多項式に対して、多項式の値が 0 になる個数が少ない x を求めることに なります。 まず、 x = 0 や などの場合、全ての多項式が 0 になります。 また、 x が の約数である場合、各項で積が となるような係数は 0 と 以外にいくつか存在することになるので、 0 になる個数が増えます。 したがって、まず最初の条件として、 x は と互いに素でなければなりません。
次に多項式の各項について、 x を何乗すると元に戻るかを考えます。 オイラー関数 には次の性質があります。
ここで、 は必ず n で割れば 1 余りますが、 だからと言って、 とは言えません。
ここで、 n が合成数の場合は、 で始めて mod n で 1 となるような要素 x は必ずしも 存在しません (素数なら必ず存在します)。
ここで値を代入します。 なので、 つまり、 31 が十分大きな k まで全て を満たしているかどうかを検証すべきです。 しかし、実際は慣習で使われています。 なお、従来は 37 や 17 などが使われていました。
次に、顧客を顧客 ID 順や名前順などに並べる方法を考えましょう。 例で示した顧客のオブジェクトは hashCode が与えられてはいますが、順番に 並べる条件は何も示していません。 このままでは順番に並びません。 そこで順番をあたえます。 Java では順番を与えるには java.lang.Comparable インターフェイスを implement し、 compareTo メソッドを実装します。
package java.lang;
public interface Comparable<T>{
int compareTo(T o);
}
オブジェクト a, b に対して、 compareTo メソッドは次のような値を返すよ うに実装します。
数学では順序と比較は似たような概念になっています。この compareTo に関 して、これが全順序関係になるには次の条件を満たす必要があり ます。
a.compareTo(a)は 0a.compareTo(b) と
-b.compareTo(a) は等しい
a.compareTo(b) と b.compareTo(c) がともに 1
なら
a.compareTo(c) も 1
さらに、オブジェクトが変化しない限りはなんど計算しても同一の答えを出さ
なければならない一貫性が求められます。
また、 a.compareTo(b)==0 の時、 a.equals(b)
が true であることが推奨されています。
このように全ての要素が比較可能で、上記の全順序の条件が成り立つ場合、必 ず、各要素は数直線のように一次元に並べることができます。 そのため、上記の条件を満たすような比較のことを全順序関係と呼びます。
なお、半順序関係とは全順序の条件に対して比較不能を許すもの です。 この場合、一直線上には並ばなくなります。 例えば、「約数である」という条件は半順序関係です。 この場合、反射律、推移律などは満たしますが、 任意の自然数の組に関して、反対称律は必ずしも成り立ちません。
例6-7 では顧客の等価条件を顧客の ID と定めましたので、 顧客の ID を順序として与えます。
class Customer implements Comparable<Customer>{
private String id;
...
/**
* 顧客の順序を与えます。
* @param 顧客オブジェクト
* @return 大小関係に応じて -1(小), 0(等), 1(大) を返します。
*/
public int compareTo(Customer customer){
return this.id.compareTo(customer.id);
}
}
このように Comparable を実装すると、 TreeSet に格納すると自然に整列さ れる他、配列に対しては java.util.Arrays.sort メソッドで整列できますし、 各 Collection に関しても Collections.sort メソッドで整列可能です。 なお、 TreeSet や TreeMap を使用する場合、compareTo が 0 であることと、 equals が true になることが一致していないと誤動作します。
import java.util.LinkedList;
import java.util.Collections;
LinkedList<Customer> customerList = new LinkedList<Customer>();
customerList.add(new Customer("..."));
...
Collections.sort(customerList); // Customer が Comparable なので整列される
オブジェクトの集まりを比較するとき、もともと与えた順序と異なる順序を考 えたい場合があります。 例えば、顧客番号以外に、名前順、購入金額順、成績順など、 さまざまな順序による整列(sort)は多くの情報処理における基本的な操作です。 オブジェクト指向言語ではこのような整列を行うために、Comparator(比 較子)と呼ばれるオブジェクトを作り、整列のメソッドに渡す手法が一 般的です。
Java で比較子を作るには、 java.util.Comparator インターフェイスを implement し、compare メソッドを実装します。
package java.util;
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
この compare は二つのオブジェクトを引数に取り、左が小さければ負の整 数、等しければ 0、左が大きければ正の整数を返します。
例えば、顧客リストに関して生年月日で順序付けを行いたい場合を考えます。 顧客の生年月日は getBirthDay メソッドで java.util.Date 型の誕生日を取 得できます。 また、 java.util.Date 自体が Comparable なので、 compareTo メソッドは 既に実装されています。 そのため、比較子は顧客オブジェクトから誕生日を取り出して、 compare に与えるだけで実現できます。
import java.util.Comparator;
class BirthDayOrder implements Comparator<User> {
public BirthDayOrder(){}
public int compare(User u1, User u2){
return u1.getBirthDay().compareTo(u2.getBirthDay());
}
}
顧客の配列があったとして、これを誕生日順に並べるには次のようにします。
User[] userList;
...
java.util.Arrays.sort(userList,new BirthDayOrder());
なお、 java.util.Comparator インターフェイスには equals メソッドも実装 するように定義されていますが、全てのクラスは java.lang.Object のサブク ラスですので、デフォルトの equals は既に実装されています。 そのため、マニュアルにあるように通常は equals は実装しません。 この equals は要素の等価性を判定するものではなく、比較子の等価性を判定 するものです。
科目名(String)ごとに点数(Integer)を持つ 成績(Seiseki)クラスを java.util.HashMap のオブジェクトをコンポジション で持つだけのクラスとして作りなさい。
実装するメソッドは次のメソッドです。メソッドの詳細は java.util.HashMap と同様ですので API のマニュアルをよく参照して実装しなさい。
class Ex1 {
/** 成績と平均点を表示します。
* @param Seiseki オブジェクト
*/
private static void showSeiseki(Seiseki s){
for(Map.Entry<String,Integer> item : s.entrySet()){
System.out.println(item.getKey()+": "+item.getValue());
}
System.out.println("平均: "+s.getAverage());
}
public static void main(String[] arg){
final Seiseki student1 = new Seiseki();
final Seiseki student2 = new Seiseki();
student1.put("データ構造とアルゴリズムI",70);
student1.put("データ構造とアルゴリズム2",80);
student1.put("情報ネットワーク",100);
student2.put("データ構造とアルゴリズムI",90);
student2.put("データ構造とアルゴリズム2",70);
student2.put("情報ネットワーク",60);
showSeiseki(student1);
showSeiseki(student2);
}
}
演習6-1 のように 成績と Java のデータ構造である Map の関係は通常は has-a 関係になります が、成績を単なる表を表すオブジェクトとみなす場合、 is-a 関係として解釈できることも あります。 そこで、成績を単なる表だと思って、 HashMap のサブクラスとして実装して みましょう。 科目名(String)ごとに点数(Integer)を持つ 成績(Seiseki)クラスを java.util.HashMap<String,Integer> のサブク ラスとして作りなさい。 そして、 double getAverage() を実装して、演習6-1 の 2 と同じプログラムに結 合しなさい。
演習6-1 において、成績を student という変数名で受けるのには違和感があ ります。 学生ごとに成績があるということは、学生(Student)と成績(Seiseki)がオブジェ クトになり、has-a 関係があることになります。 また、学生には学籍番号があるとします。 そのため、 setId, getId, getSeiseki を実装しなさい。 なお、Student のコンストラクタで成績オブジェクトを初期化しなさい。 また、さらに、 Student クラスでは学籍番号順に扱いたいので、 equals, hashCode, compareTo メソッドを実装しなさい。 そして、下記のプログラムと結合して動作を確かめなさい。 但し、Seiseki クラスは演習 1, 2 のどちらのものでも構わない。
class Ex3 {
/** 成績と平均点を表示します。
* @param Seiseki オブジェクト
*/
private static void showSeiseki(Seiseki s){
for(Map.Entry<String,Integer> item : s.entrySet()){
System.out.println(item.getKey()+": "+item.getValue());
}
System.out.println("平均: "+s.getAverage());
}
/** Student オブジェクトの配列に対して、 id を表示します
* @param Student[] 型の配列
*/
private static void showStudentId(Student[] array){
for(Student student : array){
System.out.println(student.getId());
}
}
public static void main(String[] arg){
final Student[] students = new Student[3];
for(int i=0; i < students.length; i++){
students[i] = new Student();
}
students[0].setId("07ec999");
students[1].setId("07ec990");
students[2].setId("07ec995");
students[0].getSeiseki().put("データ構造とアルゴリズムI",70);
students[0].getSeiseki().put("データ構造とアルゴリズムII",80);
students[0].getSeiseki().put("情報ネットワーク",100);
showSeiseki(students[0].getSeiseki());
showStudentId(students);
java.util.Arrays.sort(students);
showStudentId(students);
}
}
次のクラス ThreeInt には、コンストラクタで 3 つの要素を持つ int[] 型の 配列を与えて使用します。
import java.util.*;
class ThreeInt {
private int[] array;
public ThreeInt(int[] a){
array = a;
}
public int getFirst(){
return array[0];
}
public int getSecond(){
return array[1];
}
public int getThird(){
return array[2];
}
@Override public String toString(){
return Arrays.toString(array);
}
}
下記のプログラムにおいて、Arrays.sort を行ったとき、 Third のインスタンスを与えれば 3 番目の要素に対して整列、 First のインスタンスを与えれば 1 番目の要素に対して整列、 Second のインスタンスを与えれば 2 番目の要素に対して整列するように、 それぞれ Comparator<ThreeInt> としてクラスを作りなさい。
class Ex {
private static void show(ThreeInt[] array){
for(ThreeInt t : array){
System.out.println(t);
}
System.out.println("---------");
}
public static void main(String[] arg){
ThreeInt[] tArray = { new ThreeInt(new int[]{1,2,3}),
new ThreeInt(new int[]{2,3,1}),
new ThreeInt(new int[]{3,1,2})};
show(tArray);
Arrays.sort(tArray, new Third());
show(tArray);
Arrays.sort(tArray, new First());
show(tArray);
Arrays.sort(tArray, new Second());
show(tArray);
}
}
[1, 2, 3] [2, 3, 1] [3, 1, 2] --------- [2, 3, 1] [3, 1, 2] [1, 2, 3] --------- [1, 2, 3] [2, 3, 1] [3, 1, 2] --------- [3, 1, 2] [1, 2, 3] [2, 3, 1] ---------