
C の構造体と変数
このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
前回は C 言語と Java 言語でそれぞれ関数の取扱い方法について説明しました。 基本的な文法はほぼ同じですが、 Java には class とアクセス修飾子という C 言語にない機能がありました。 今回は C 言語と Java 言語の特徴を説明しながらプログラム開発について説 明します。
コンピュータで計算を行う場合、データを扱うためにプログラム言語では変数 を用います。 その際、数値データ、文字データなどデータ自体には 型 と呼ば れる性質があります。 型に応じてプログラミング言語はデータの扱い方が変化します。 例えば、たし算が可能かとか、表示する時に小数点を打つかなど。
C 言語ではプログラミング言語としてあらかじめ扱い方が定められている型 (基本型)として次の型があります。
これらの型はあらかじめ用意されており、この型で変数を宣言することにより、 その型のデータを取り扱うことができます。
int main(void){
float f=3.1;
double pi=3.141592653;
char c='a';
int i=123;
long l=1234567890;
printf("%f %f %c %d %ld\n",f,pi,c,i,l);
}
C 言語では基本型の他、ユーザが定義可能な次のデータ型を持っています。
二次元の点を扱う struct の例
#include <stdio.h>
#include <math.h>
struct Point {
double x;
double y;
};
double distance(struct Point p){
return sqrt(p.x*p.x+p.y*p.y);
}
void showPoint(struct Point p){
printf("点 %f,%f ",p.x,p.y);
}
int main(void){
struct Point p={3.0,4.0};
struct Point q;
q=p; // コピー
q.x+=1.0;
showPoint(p);
printf("の原点からの距離は %f\n",distance(p));
showPoint(q);
printf("の原点からの距離は %f\n",distance(q));
return 0;
}
enum をつかって、状態を名前で保持して switch case 文で処理する例
#include <stdio.h>
enum STATUS {first, second, final};
int main(void){
enum STATUS status=first;
while(status != final){
switch(status){ /* switch case 利用可能 */
case first:
printf("最初\n");
status = second;
break;
case second:
printf("次\n");
status = final;
break;
}
}
printf("終了\n");
return 0;
}
union を使って、 double のデータ構造の内部にアクセスし、値をいじる例
#include <stdio.h>
union FUDOU {
double value; /* 同一領域を異なる型で */
char byte[sizeof(double)]; /* アクセス可能 */
};
void showByte(union FUDOU x){
int i;
for(i=0;i<sizeof(double);i++){
printf("%.2x ",x.byte[i]&0xff);
}
printf("\n");
}
int main(void){
int i;
union FUDOU x,y,z;
x.value=1.0;
y.value=2.0;
z.value=4.0;
showByte(x);
showByte(y);
showByte(z);
y.byte[6]=0x10;
showByte(y);
printf("%f\n",y.value);
return 0;
}
union, enum, struct を全部使って、一つの配列に int, double, 文字列を入 れる例
#include <stdio.h>
enum TYPE { INT, DOUBLE, STRING };
union DATA {
struct {
enum TYPE type;
} t;
struct {
enum TYPE type;
int data;
} ti;
struct {
enum TYPE type;
double data;
} td;
struct {
enum TYPE type;
char * data;
} ts;
};
void showData(union DATA d){
switch(d.t.type){
case INT:
printf("%d\n",d.ti.data);
break;
case DOUBLE:
printf("%f\n",d.td.data);
break;
case STRING:
printf("%s\n",d.ts.data);
break;
}
}
int main(void){
int i;
union DATA data[3];
data[0].ti.type=INT;
data[0].ti.data=4;
data[1].td.type=DOUBLE;
data[1].td.data=3.14;
data[2].ts.type=STRING;
data[2].ts.data="abcd";
for(i=0; i<3; i++){
showData(data[i]);
}
return 0;
}
C 言語では変数の呼び出し方法を管理する変数として、ポインタ型という変数 型があります。 ポインタ型は端的に言って、変数の値が格納されているメモリの番地を記憶す る変数型です。 格納されている本来のデータ型を保持するために、各データ型に対して、対応 するポインタ型があります。 つまり、例えば int 型の変数のメモリの番地を記憶するのには int のポイン タ型という変数型があります。
変数のメモリの番地は変数名の前に & 記号を付けると得られます。 一方、このポインタ型の変数を宣言するには、宣言時に変数名の前に * 記号 を付けます。 ポインタ型の変数を番地の計算に使う時は、通常の変数名を使用します。 また、ポインタ変数が指すメモリに入っている値を取り出すには変数の前に * 記号を付けます。
#include <stdio.h>
int main(void){
int x=3;
int y=4;
int *z; /* ポインタ変数の宣言 */
printf("%p %p\n",&x,&y); /* 変数の番地 */
z=&x; /* アドレスの代入 */
printf("%p %d\n",z,*z); /* ポインタの指す値の取得 */
z=&y;
printf("%p %d\n",z,*z);
return 0;
}
配列変数は実際はポインタに近い存在です。 配列の宣言は宣言に従った量のメモリを確保し、変数名に番地を入れます。 ポインタの値に整数値を加減する場合、実際には変数の型に応じて、次の値を 示すように加算されます。 また、配列を関数に渡すときは、配列名の変数のみを渡し、受け側はポインタ で受けます。
#include <stdio.h>
void printThree(double *p){ /* ポインタの仮引数 */
printf("%f %f %f\n",p[0],p[1],p[2]);
/* ポインタ変数の配列表記 */
}
int main(void){
double a[]={1.0,2.0,3.0};
double *b;
printThree(a);
b=a; /* ポインタ変数へ配列変数の代入 */
printThree(b);
printf("%p %p\n",a,b);
b++; /* ポインタの加算 */
printf("%f %f\n",a[1],*b);
printf("%p %p\n",&a[1],b);
return 0;
}
つまり、 &a[0] と a の値は等しく、また、 a[0] と *a の値は等しくなります。 さらに、ポインタは加算などができます。 但し、 1 を加えても番地が一つ増えるわけではなく、1 を加えると一つ次の 値を指すようになります。 つまり、 &a[1] と a+1 の値は等しく、また、 a[1] の値と *(a+1) の値 は等しくなります。
ポインタがあることによって、関数に変数を渡したり、動的なメモリ管理を可 能にしたり、関数呼び出しを変数によって制御を行ったりと多彩なコントロー ルが可能になります。
但し、メモリーの番地計算に関するミスに関してはコンパイラでは一切チェッ クができないので、高度な処理が行える半面、生産性を高く保つのが難しくな ります。
C 言語ではプログラムは {} のカッコの中に記述します。 これを ブロック と呼びます。 その際、プログラムは宣言部と手続き部に分かれますが、ブロック内に宣言され た物はブロック外からは原則的にアクセスできません。 これをローカル変数と呼びます。 従って、 main 関数内部で宣言された変数の値を、他の関数から変更すること はできません。 但し、関数へ変数のポインタを渡すことで、関数からの変更を可能になります。
#include <stdio.h>
void swap(double *x,double *y){
double z;
z=*x;
*x=*y;
*y=z;
}
int main(void){
double a=2.0;
double b=3.0;
printf("%f %f\n",a,b);
swap(&a,&b);
printf("%f %f\n",a,b);
return 0;
}
一方、関数やブロックの中ではなく、一番外部でも変数宣言ができます。 これを グローバル変数 と言います。 グローバル変数はすべての関数から変更可能です。 初期の BASIC 言語などではすべての変数はグローバル変数でした。 これはプログラム言語としての取扱いのルールは簡単ですが、プログラミング (例えば修正など)が複雑になります。 例えば、グローバル変数関連で処理の誤りがあるとわかっても、どの関数の処理に誤 りがあるかの判別が難しくなります。
C 言語は大きなプログラムを作れるような仕組みとして、 分割コンパイル というプログラム開発手法をとることができます。 これは、単純に言えば、関数毎に別ファイルにし、それぞれの関数毎にコンパ イルが可能であるということです。 そして、コンパイルされた関数同士を任意に組み合わせて実行可能なプログラ ムに組み立てることが可能です。 この手法により、関数毎にコンパイルエラーを取ることができる長所がありま す。 またそれだけではなく、コンパイルした関数を本来結合されるべき他の関数と 組み合わせて実行可能形式にできる一方で、テスト用の関数と結合してテスト プログラムを作成することもできます。
C 言語での static 修飾子には次のような意味があります。
#include <stdio.h>
int ex1(void){
int res=0;
return ++res;
}
int ex2(void){
static int res=0;
return ++res;
}
int main(void){
printf("%d\n",ex1());
printf("%d\n",ex1());
printf("%d\n",ex2());
printf("%d\n",ex2());
return 0;
}
関数宣言に static 修飾をすると、その関数の利用できる範囲が同一ファ イル内に限られ、結合時に他のファイルの関数から呼び出しができなくなり ます。
基本的には C 言語において関数名はプログラム全体に対して唯一でなければ なりません。 しかし、巨大なプログラム開発において、今話題にしているような関数化によ る抽象化を行う場合、プログラム全体において関数名の管理は困難になりま す。 このような場合、ファイル間で相互に呼び出しが想定される関数以外は static 修飾をすることにより、他のファイルから関数宣言を隠蔽すること ができます。
同様にグローバル変数に static 修飾すると、他のファイルから extern 宣言されてもアクセスができなくなります。 前項と同様に、グローバル変数名を他のファイルから隠蔽できるので、グロー バル変数の名前を全体で管理する必要がなくなります。
Java は基本的には C 言語を元に作られたので、共通部分が多いです。 しかし、次のような点で大きく異なっています。
Java では C 言語同様に int, long, float, double, char などの型があります。 付け加えて byte, boolean というバイト、論理値の型があります。 但し、文字列は char の配列として処理をしません。 文字列は java.lang.String というオブジェクトクラスになります。
オブジェクトはデータを保持し、保持しているデータに対して メソッドと呼ばれる関数を実行します。 C 言語で説明した二次元上の点を扱うようなことも同様に処理できます。
但し、 Java のオブジェクトは変数宣言では作られません(C++ では作られま す)。 Java でオブジェクトを作るには、オブジェクトのクラスを定義し、生成する 関数などを呼ぶ必要があります。 特に、オブジェクトクラス内にクラス名と同一の名前で、戻り値の指定無しの メソッドをコンストラクタ と呼びます。 new 演算子 でコンストラクタを呼ぶとオブジェクトが生成されま す。 つまり、 Java では基本型とオブジェクト型の変数の扱いはまったく違います。 したがって、例2-2 を機械的に Java に移行すると次のようになります。
例2-2の Java 版(問題あり)
class Point {
public double x;
public double y;
public Point(double x, double y){ // コンストラクタ
this.x=x;
this.y=y;
}
}
class Rei22 {
private static double distance(Point p){
return Math.sqrt(p.x*p.x+p.y*p.y);
}
private static void showPoint(Point p){
System.out.print("点 "+p.x+","+p.y+" ");
}
public static void main(String[] arg){
Point p = new Point(3.0,4.0); //1
Point q; //2
q = p; //3
q.x += 1.0;
showPoint(p);
System.out.println("の原点からの距離は "+distance(p));
showPoint(q);
System.out.println("の原点からの距離は "+distance(q));
}
}
ここで、コンストラクタで使われている this は自身のオブジェクトを指すもの です。 引数とオブジェクト変数を区別するにはこのようにオブジェクト変数に this を指定します。 また、 Point クラス中のメンバ変数やメンバ関数はすべて外部 (Rei22) から アクセスするので public で宣言されていることに注意してください。
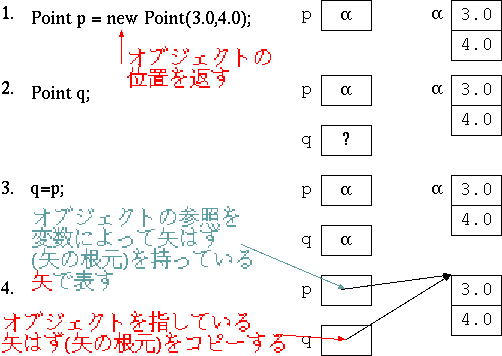
ところで、実はこのプログラムは例2-2 と結果は同じになりません。
これはなぜかというと、 C 言語では struct の変数宣言をすると、その
struct の変数の領域が確保されるからです。
具体的には struct Point q; と宣言すると、構造体にデータを
格納するためのメモリが確保されます。
また、 q = p; とすると、 p の内容が q にコピーされます。
一方、 Java のオブジェクト型の変数宣言は、オブジェクトを生成したり、メモリ
を確保したりしません。
Java のオブジェクト型の変数はむしろ C 言語のポインタと同様に、オブジェクトが
確保したメモリの番地を指すための領域しか確保しません。
そのため、上記の Java のプログラムにおいて、 q = p; とす
ると、コピーされるのではなく単に q と p が同じオブジェクトを指すように
なるだけです。
このようにオブジェクトを指し示すことを参照と言います。
C の構造体と変数
Java のオブジェクトと変数
なお、 C 言語ではポインタはメモリのアドレスを表すため、足し算などのア ドレス計算ができましたが、Java では参照に対して加算などの演算をするよ うなことはできません。
さて、このプログラムを改良することを考えましょう。 プログラムの中に、Point と Rei22 というふたつのクラスがあります。 このプログラムにおいて、distance と showPoint というふたつの関数は Rei22 というクラスの所有になっています。 しかし、この関数の意味を考えると、両方共 Point 型の変数の処理をする だけの関数です。 つまり、特に Rei22 に存在する意味はありません。 従って、これらの関数はともに Point クラスに移動すべきです。 なお、Point クラスに移動した関数を Rei22 クラス内からアクセスするには public 宣言する必要があります。 また、外部から他のクラス中の関数を呼ぶときは、「クラス名.関数名(...)」 の書式で呼びます。
class Point {
public double x;
public double y;
public Point(double x, double y){
this.x=x;
this.y=y;
}
public static double distance(Point p){
return Math.sqrt(p.x*p.x+p.y*p.y);
}
public static void showPoint(Point p){
System.out.print("点 "+p.x+","+p.y+" ");
}
}
class Rei22 {
public static void main(String[] arg){
Point p = new Point(3.0,4.0);
Point q;
q = p;
q.x += 1.0;
Point.showPoint(p);
System.out.println("の原点からの距離は "+Point.distance(p));
Point.showPoint(q);
System.out.println("の原点からの距離は "+Point.distance(q));
}
}
ここで、さらに、これらの関数の引数に注目します。 引数がそのクラスのオブジェクト一個である関数をオブジェクトに対する メソッドにします。 つまり、引数に対する関数をオブジェクトに対するメソッドにしてしまいます。 具体的には引数リストからそのオブジェクトを取り除き、 static 修飾子を取 り除くだけです。 では、まず Point.showPoint(p) という関数呼び出しをメソッドに変更しましょ う。 これは、p が Point 型であって、それを表示する というメソッドになるので、 Point というキーワードが既に冗長です。 つまり、意味を考えると p を show するだけで良いので、呼び出し方法は 「 p.show() 」としましょう。 同様に distance もこの変更をしたのが次の例です。
class Point {
public double x;
public double y;
public Point(double x, double y){
this.x=x;
this.y=y;
}
public double distance(){
return Math.sqrt(x*x+y*y);
}
public void show(){
System.out.print("点 "+x+","+y+" ");
}
}
class Rei22 {
public static void main(String[] arg){
Point p = new Point(3.0,4.0);
Point q;
q = p;
q.x += 1.0;
p.show();
System.out.println("の原点からの距離は "+p.distance());
q.show();
System.out.println("の原点からの距離は "+q.distance());
}
}
Java で作成したオブジェクトの性質として、何も定義しなくても java.lang.Object のメソッドが利用できます。 その中で、特に重要なメソッドとして equals, toString があります。
API マニュアルの java.lang.Object の toString メソッドの欄に書い てありますが、全てのクラスでこの toString が人間が読める簡潔な表現であ る文字列を返すように定義すべきです。 例えば、上で定義した Point クラスに関しても、文字列表現を toString で得られ るようにすると良いです。 toString メソッドを定義しておくと、文脈上オブジェクトが文字列として解 釈すべき状況の時、自動的に toString メソッドが呼ばれます。
例えば、 System.out.println(p); という構文で、 p がオブジェ
クトである場合を考えます。
package java.io;
public class PrintStream {
public void println(Object o){
print(String.valueOf(o));
println();
}
}
package java.lang;
public class String {
public String valueOf(Object o){
if(o == null){
return "null";
}
return o.toString();
}
}
これが各クラスで toString の定義が推奨される理由です。
したがって、 System.out.println(p); というプログラムを実
行すると p.toString() の値が表示されます。
また、Java では文字列に関して + 記号が結合の意味を持ちます。
そのため、 x+y という構文において、少なくとも一方が文字列の時は両
方共文字列として解釈されます。
つまり "here :"+pというような式を書くと、
"here :"+p.toString() という値が計算されます。
そのため、今議論している Point クラスに対しても、 show() で Point を表 示せず、 toString で文字列を返して main 内で表示させるように改良します。
なお、上記の議論で、 q = p でコピーが作られないことが、 C 言語でのプログラム と動作が一致しない原因でした。 そこで、応急措置でコピーを実現できるコンストラクタ (コピーコンストラクタ)を作ります。 これは、クラスのオブジェクトを与えるコンストラクタです。 新しいオブジェクトを作る際に、与えられたオブジェクトの値を内部でコピー して同じ値を持つオブジェクトを返します。 なお、オブジェクトのコピーに関してはさまざまな議論がありますので、詳し い議論は章を改めることにします。
class Point {
public double x;
public double y;
public Point(double x, double y){
this.x=x;
this.y=y;
}
public Point(Point p){//コピーコンストラクタ
this.x = p.x;
this.y = p.y;
}
public double distance(){
return Math.sqrt(x*x+y*y);
}
public String toString(){
return "点 "+x+","+y;
}
}
class Rei22 {
public static void main(String[] arg){
Point p = new Point(3.0,4.0);
Point q;
q = new Point(p); //コピー
q.x += 1.0;
System.out.println(p+" の原点からの距離は "+p.distance());
System.out.println(q+" の原点からの距離は "+q.distance());
}
}
C 言語の配列はポインタと密接でしたが、 Java の配列はオブジェクトと近い です。 つまり、配列変数の宣言では配列は作られず、 new 演算子でオブジェクトの ように生成します。 また、メソッドのようなものをいくつも持っています。
class Rei23 {
public static void main(String[] arg){
double[] a= {3.0, 1.0, 4.0, 1.0, 5.0};
for(int i=0; i<a.length; i++){
System.out.println(a[i]);
}
}
}
まず、配列の宣言は型の後ろに [] を付けることで配列を意味します。 また、「配列変数.length」の構文で配列の要素数を返します。 なお、 Java では配列変数は参照であり、 C 言語のように宣言時に領域は確 保されません。 領域を確保するには new 演算子を使用します。 また配列変数から配列変数への代入は単に同じ配列を指すだけです。 コピーするには clone() メソッドを使います。
class Rei24 {
private static void fill(double[] x){
for(int i=0; i<x.length; i++){
x[i]=2.0+i;
}
}
private static void showArray(double[] x){
for(int i=0; i<x.length; i++){
System.out.print(x[i]+" ");
}
System.out.println();
}
public static void main(String[] arg){
double[] a = new double[10];
double[] b = new double[3];
double[] c; // 領域は作られない
fill(a);
fill(b);
showArray(a);
showArray(b);
b=a;
c=a.clone(); // コピー
a[2]=100.0;
showArray(a);
showArray(b);
showArray(c);
}
}
配列は参照型なので、関数の引数に指定して、関数で値を変更すると配列の内 容を変化させることができます。
また、上記のように配列に含まれる全ての要素を順にアクセスすることはしば しば行う処理です。 そのため、これを簡便に行うため、 Java 5 から foreach 構文が 導入されました。 配列の値を取り出すだけで、しかも、ループ変数の値が必要でないときは foreach 構文を使用します。
class Rei24 {
private static void fill(double[] x){
for(int i=0; i<x.length; i++){
x[i]=2.0+i; // ループ変数を使用
}
}
private static void showArray(double[] x){
for(double y : x){ // foreach 構文
System.out.print(y+" ");
}
System.out.println();
}
public static void main(String[] arg){
double[] a = new double[10];
double[] b = new double[3];
double[] c;
fill(a);
fill(b);
showArray(a);
showArray(b);
b=a;
c=a.clone();
a[2]=100.0;
showArray(a);
showArray(b);
showArray(c);
}
}
なお、配列と同等の処理が可能なオブジェクトクラスとして、 java.util.ArrayList が用意されています。 こちらは要素数が増えても自動的に領域が拡張されるなどの機能があります。 なお、 ArrayList をコピーするには、配列同様に clone メソッドを使います。 clone メソッドで作られたオブジェクトは java.lang.Object 型になるので 元の型にキャストする必要があります。 ArrayList の用法は後に詳しく説明します。
import java.util.ArrayList;
class Rei25 {
private static void fill(ArrayList<Double> x, int n){
for(int i=0; i<n; i++){
x.set(i,2.0+i);
}
}
private static void showArray(ArrayList<Double> x){
for(Double y : x){
System.out.print(y+" ");
}
System.out.println();
}
public static void main(String[] arg){
ArrayList<Double> a = new ArrayList<Double>();
ArrayList<Double> b = new ArrayList<Double>();
ArrayList<Double> c;
fill(a,10);
fill(b,3);
showArray(a);
showArray(b);
b=a;
c=(ArrayList<Double>) a.clone();
a.set(2,100.0);
showArray(a);
showArray(b);
showArray(c);
}
}
さらに java.util.Arrays クラスには検索や並べ替えなどの様々な配列への便 利な関数が用意されています。
既にいろいろな文字列の扱いをしてきましたが、ここで Java での文字列の扱 いについてまとめます。 まず、 C 言語では文字列は char の配列でしたが、 Java では java.lang.String というオブジェクトになります。 java.lang.String には様々なメソッドがあり、文字列の長さ、特定文字の抽 出、検索などができます。 但し、文字列を変更することはできません。 例えば、 toUpperCase() メソッドは文字列を大文字に変換するのではなく、 文字列を大文字に変換した新たな文字列を生成します。
文字列に対して、 + 演算子は文字列を接続します。 "a"+"b" は "ab" という文字列を返します。 また、一方が文字列で他方が int や double などの基本型、あるいはオブジェ クトの場合はすべて文字列に変換して接続されます。 "1"+1 は "11" に変換されます。
C 言語では、あらゆるデータに対して、ポインタという手法で統一的に扱うこと ができます。 これは、 int 型でも struct による構造型でもポインタ変数で参照できると いうことです。 しかし、 Java において参照が可能なのはオブジェクトと配列などで、基本型 を直接参照する方法はありません。
例2-15では java.util.ArrayList のオブジェクトに double 型のデー タを入れていますが、よく見ると double 型の指定ではなく Double を指定し ています。 実はこの Double というのは java.lang.Double というオブジェクトクラスで、 これはラッパークラスと呼ばれるものです。 基本型 double をオブジェクトと同様に扱うために導入されたクラスです。
Double クラスの基本的な使用法はコンストラクタに値を入れてオブジェクト にすることと、 doubleValue() メソッドにより入れた値を取り出すことです。 つまり、オブジェクトその物には数値を計算する機能はありません。 そのため、オブジェクト的な扱いをするときはラッパークラスに変換し、計算 をするときは値を取り出すという操作をする必要があります。
class Rei26 {
public static void main(String[] arg){
double d1 = 2.0;
double d2 = 3.0;
System.out.println(d1+d2);
Double d3 = new Double(2.0);
Double d4 = new Double(3.0);
System.out.println(d3.doubleValue()+d4.doubleValue());
}
}
ところが、 Java 5 からオートボクシング、オートアンボクシングという機能 が加わりました。 これは文脈で基本型とラッパークラスの変換を自動的に行ってくれるというも のです。 次の例は自動的に上の例2-16のように変換されます。 なお、ラッパークラスの機能が拡張されたのではなく、コンパイラが自動変換 するだけであることに注意してください。
class Rei26 {
public static void main(String[] arg){
double d1 = 2.0;
double d2 = 3.0;
System.out.println(d1+d2);
Double d3 = 2.0;
Double d4 = 3.0;
System.out.println(d3+d4);
}
}
つまり、変数の必要がなくなったのではなく、自動的に変換されるだけです。 そのため、計算を多用する場合は、基本型を使って値を保持すべきです。
ラッパクラスの用法の例を示します。 あらゆるオブジェクトは java.lang.Object 型の変数で参照できます。 そのため、C 言語の例2-5 で示したような、一つの配列に int, double, 文 字列を入れるようなことは、実は次のような簡単なプログラムで実現できます。
class Rei27 {
public static void main(String[] arg){
Object[] data = new Object[3];
data[0]=4;
data[1]=3.14;
data[2]="abcd";
for(Object o : data){
System.out.println(o);
}
}
}
これは
data[0] = new Integer(4);,
data[1] = new Double(3.14);,
とオートボクシングにより変換され、
System.out.println(o) で、Integer, Double, String に含ま
れる toString 関数がそれぞれ呼ばれるためです。
オブジェクト指向の利点の一つは、プログラムを細分化できることです。 その際、細分化したもの同士がなるべく関連付かない方が、後々の修正やリファ クタリングをしやすくなります。 また、作成したクラスを利用する際にも、必要な機能以外の情報はなるべく少 ない方がプログラムを作りやすくなります。 不必要な情報をクラスの外部に出さずに内部に止めることを カプセル化 と言います。
カプセル化を行うには、基本的にはすべてのメンバを private 宣言し、外部 で使用するものだけを public 宣言します。 但し、変数のアクセスに関してクラスで積極的にコントロールするための基本 手法として、変数をすべて private 宣言し、 public な読み出し、書き込み に対するメソッドを作る方法があります。 変数を読み出すメソッドを getter、書き込むメソッド を setterと呼びます。 例2-11ではメンバ変数は public 宣言されてましたが、これを private 宣言 して、 getter, setter に変えた例を示します。
class Point {
private double x;
private double y;
public double getX(){return x;}
public double getY(){return y;}
public void setX(double x){this.x=x;}
public void setY(double y){this.y=y;}
public Point(double x, double y){
setX(x); //this.x=x; でも良い
setY(y);
}
public Point(Point p){
setX(p.getX());
setY(p.getY());
}
public double distance(){
return Math.sqrt(x*x+y*y);
}
public String toString(){
return "点 "+x+","+y;
}
}
class Rei22 {
public static void main(String[] arg){
Point p = new Point(3.0,4.0);
Point q;
q = new Point(p);
q.setX(q.getX()+1.0);
System.out.println(p+" の原点からの距離は "+p.distance());
System.out.println(q+" の原点からの距離は "+q.distance());
}
}
このような短いプログラムでは getter, setter の利点はあまりはっきりし ません。 ただ、関数の内部や、private 宣言しているものはどのように変化しても外部 のプログラムに影響を与えませんので、例えば、変数自体が存在しなくてデー タベースへの値の格納になっていても、外部は getter, setter を使用している 限りではプログラムの変更はありません。
Java 5 から列挙型がオブジェクト指向的な手法で追加されました。 用法は複雑なので、データ構造とアルゴリズム II で詳しく説明します。
つぎの C プログラムを Java のプログラムに変えなさい。
#include <stdio.h>
int main(void){
double data[]={3.0,1.0,4.0,1.0,5.0,-1.0};
int i;
double sum=0.0;
for(i=0; data[i]!=-1.0; i++){
sum += data[i];
}
printf("%f \n",sum);
return 0;
}
#include <stdio.h>
#include <math.h>
double heron(double a, double b, double c){
double s=(a+b+c)/2;
return sqrt(s*(s-a)*(s-b)*(s-c));
}
int main(void){
double x,y,z;
x=2.0;
y=3.0;
z=4.0;
printf("三辺の長さが %f, %f, %f の三角形の面積は",x,y,z);
printf("%f\n",heron(x,y,z));
return 0;
}
Java の平方根は java.lang.Math クラスにあります。
#include <stdio.h>
struct nijiHouteishiki {
double a;
double b;
double c;
};
void printHouteishiki(struct nijiHouteishiki g){
printf("%f x^2 %+f x %+f = 0",g.a,g.b,g.c);
}
double discriminant(struct nijiHouteishiki g){
return g.b*g.b-4*g.a*g.c;
}
int main(void){
struct nijiHouteishiki f={2.0,5.0,3.0};
printHouteishiki(f);
printf("の判別式の値は %f\n",discriminant(f));
return 0;
}
Java.lang.String クラスに format 関数があります。 それを使うと sprintf と同じように文字列を生成できます。
#include <stdio.h>
struct nijiHouteishiki {
double a;
double b;
double c;
};
void printHouteishiki(struct nijiHouteishiki g){
printf("%f x^2 %+f x %+f = 0",g.a,g.b,g.c);
}
double discriminant(struct nijiHouteishiki g){
return g.b*g.b-4*g.a*g.c;
}
int hasRealRoot(struct nijiHouteishiki g){
return discriminant(g)>=0;
}
int main(void){
struct nijiHouteishiki f={2.0,5.0,3.0};
printHouteishiki(f);
printf("は実根を");
if(hasRealRoot(f)){
printf("持つ\n");
}else{
printf("持たない\n");
}
return 0;
}
C 言語では論理値は int で表しますが、 Java は boolean 型です。
#include <stdio.h>
struct nijiHouteishiki {
double a;
double b;
double c;
};
void printHouteishiki(struct nijiHouteishiki g){
printf("%f x^2 %+f x %+f = 0",g.a,g.b,g.c);
}
double discriminant(struct nijiHouteishiki g){
return g.b*g.b-4*g.a*g.c;
}
int numberOfRoots(struct nijiHouteishiki g){
if(discriminant(g)>0){
return 2;
}
if(discriminant(g)==0){
return 1;
}
return 0;
}
int main(void){
struct nijiHouteishiki f={2.0,5.0,3.0};
printHouteishiki(f);
printf("は %d 個の実根を持つ\n",numberOfRoots(f));
return 0;
}