このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
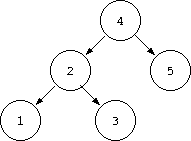
順序木は、値の大小に基づいて値を格納する木です。 順序木を使うと低いコストで値を小さい順に取り出すことが可能になります。 順序木とは、各頂点に値を持つ二分木のうち、次の性質を持つものです。
順序木は、部分木も順序木になっているという性質があります。 そのため、プログラムは帰納的に定義可能です。 例えば、このような性質を持っている木に対して新たな値を格納することを考 えます。 値を格納できる場所を探す際、各頂点の持つ値と比較していくことで、頂点の 右の枝の方面か左の枝の方面か選ぶことができます。 ここで、帰納的な定義を考えると次のように書けます。
ここで、データの追加とは、部分木が無い場合はそこに頂点を追加し、そうで なければその部分木に対して add(data) を行うことを指します。
このような手続きをとることにより、木の葉の部分に頂点を追加することにな ります。 そのため、木の深さ分だけ値を比較することで挿入可能な場所を捜し出せること になります。 木の深さは、都合が良い場合で全頂点数 N に対して log N 程度になりますので、挿入の手間もその程度で収まります。 また、最小、最大の値もそれぞれ木の一番左と右の要素になりますから、やは り木の深さ程度の手間で見つけられます。
また、同様にして、全データの昇順の取り出し方法も帰納的に考えることがで きます。 これは、注目している頂点に対して、左側の部分木のデータは常に小さく、右 側の部分木のデータは常に大きいという性質を使います。 そのため、左を取り出し、根のデータを取り出し、右を取り出すという手順を 帰納的に記述すればよいことになります。
オブジェクト指向分析では、線形リストと同様に、「木」と「頂点」は別オブ ジェクトになります。 そのため、「頂点」の集まりを「木」として管理することになります。 これをここではそれぞれ Choten と Ki いう名前にします。 頂点は他の頂点へ接続するとともにデータを補完しますので、Generics を使 うと次のように書くことができます。
class Choten<E> {
Choten<E> left,right;
E data;
public Choten(E data){
this.data = data;
}
}
public class Ki<E> {
private Choten<E> root; // 管理変数
}
なお、Choten のメンバ変数は SenkeiList で操作する可能性がありますので、 private でも protected でも public でもない、同一パッケージ内でのアク セスを許す無指定にしておきます。
さて、まず、このデータ型でデータの追加を考えます。 線形リストでは nil と呼ぶ空の頂点を番兵として利用することで、管理変数 への代入はコンストラクタのみに限定することができました。 しかし、木の場合、空の葉を木に含めるとデータ数と同じ数だけ空の葉が必要 になってしまいます。 そのため、その手法は取らないことにします。 そこで、頂点からの参照が null か否かで頂点の存在を検出することにします。
するとデータの追加は次のように書けます。
class Ki<E> {
...
public void add(E data){
if(root==null){
root = new Choten<E>(data);
return;
}
root.add(data);
}
}
class Choten<E> {
public void add(E data){
if(this.data より data が小さい){ // ※
if(left==null){
left = new Choten<E>(data);
return;
}
left.add(data);
}else{
if(right==null){
right = new Choten<E>(data);
return;
}
right.add(data);
}
}
}
追加に関しては上記のように再帰的に定義することで簡潔に記述できます。
しかし、 ※の部分に問題があります。 Java では Generics であろうとなかろうと、クラス毎にコンパイルできるこ とになっています。 そのため、 this.data と data の比較を行う際に、比較方法がこのクラスの 定義だけで完結しなければなりません。 さて、オブジェクトの大小比較を行うには java.lang.Comparable インターフェ イスにある compareTo を使用します。そのため、上記の※部分の条件も compareTo を使用して記述すべきです。 そのためには、クラス E 自体が Comparable でなければなりません。 Generics では型引数が別のクラスを extends していようが、implements し ていようがどちらでも extends と指定します。 そのため、とりあえず上記のプログラムは次のようになります。
class Ki<E extends Comparable<E>> {
...
public void add(E data){
if(root==null){
root = new Choten<E>(data);
return;
}
root.add(data);
}
}
class Choten<E extends Comparable<E>> {
public void add(E data){
if(this.data.compareTo(E.data)<0){ // ※
if(left==null){
left = new Choten<E>(data);
return;
}
left.add(data);
}else{
if(right==null){
right = new Choten<E>(data);
return;
}
right.add(data);
}
}
}
しかし、これではまだ問題があります。 次の例をコンパイルして見てください。 これは与えられたクラスをコンポジションして Comparable なクラスにするク ラスを作ろうしています。
class A<E extends Comparable<E>>
implements Comparable<A<E>>{
private E data;
public A(E data){
this.data = data;
}
public int compareTo(A<E> x){
return this.data.compareTo(x.data);
}
}
class C1 implements Comparable<C1> {
int value;
public C1(int n){
value = n;
}
public int compareTo(C1 obj){
return value - obj.value;
}
}
class C2 extends C1 {
public C2(int n){
super(n);
}
}
class Test {
public static void main(String[] arg){
final A<C1> a11 = new A<C1>(new C1(2));
final A<C1> a12 = new A<C1>(new C1(4));
System.out.println(a11.compareTo(a12));
/*
*/ //†
final A<C2> a21 = new A<C2>(new C2(2)); // ※
final A<C2> a22 = new A<C2>(new C2(5)); // ※
System.out.println(a21.compareTo(a22));
/**/
}
}
class Test2 {
public static void main(String[] arg){
C1 c11 = new C1(1);
C1 c12 = new C1(2);
C2 c21 = new C2(3);
C2 c22 = new C2(4);
System.out.println(c11.compareTo(c12));
System.out.println(c21.compareTo(c22));
}
}
上記では ※ の部分でコンパイルエラーが出ます。 というのは、C2 は Comparable<C2> を実装していないからです。 C2 は Comparable<C1> のクラス C1 のサブクラスなので、 Comparable<C1> ではありますが、 Comparable<C2> ではありま せん。 但し、 C2 のオブジェクト x,y に関して、 x.compareTo(y) は C1 から継承されてい るため、実行可能です。 上記の // † の行を消すと、コンパイルに成功して、 Test と Test2 が出来上 がります。 この Test2 では c21.compareTo(c22) は正常に動作します。
さて、これに対して、 C2 に implements Comparable<C2> と指定する ことが考えられます。 しかし、 「 java.lang.Comparable を異なる引数 <C2> と <C1> で継承す ることはできません。」というエラーが出てコンパイルできません。 つまり、親クラスで Comparable を実装した場合、子クラスで compareTo を オーバーライドしても、新たに Comparable の型引数を子クラスに格上げでき ません。
結局 A の持つ型引数 <E extends Comparable<E>> を変更するこ とで対処するしかありません。 ここで、先ほどの議論で、「E の先祖のクラスが Comparable を実装している」という 条件を考えましょう。 すると、 compareTo は常に子孫クラスで public なメソッドになりますので、 いずれにしろオブジェクトに対して compareTo を実行することができます。 E の先祖のクラスを F とすると、 F においては implements Comparable<F> を指定し、 compareTo を public メソッドとして実装して いたはずです。 つまり、 E は Comparable<F> になっています。 そこで、上記のクラス定義では、 <E extends Comparable< E の先祖 >> を指定すれば良いことになります。 ここで「自分の祖先のどれかのクラス」というのはワイルドカードと super キーワードを使って? super Eと表すことができます。 したがって、上記の例を Comparable<E> から Comparable<? super E>に置き換えると上記のプログラムはコンパイル、 動作できるようになります。
class A<E extends Comparable<? super E>>
implements Comparable<A<E>>{
private E data;
public A(E data){
this.data = data;
}
public int compareTo(A<E> x){
return this.data.compareTo(x.data);
}
}
class C1 implements Comparable<C1> {
int value;
public C1(int n){
value = n;
}
public int compareTo(C1 obj){
return value - obj.value;
}
}
class C2 extends C1 {
public C2(int n){
super(n);
}
}
class Test {
public static void main(String[] arg){
final A<C1> a11 = new A<C1>(new C1(2));
final A<C1> a12 = new A<C1>(new C1(4));
System.out.println(a11.compareTo(a12));
/*
*/ //†
final A<C2> a21 = new A<C2>(new C2(2)); // ※
final A<C2> a22 = new A<C2>(new C2(5)); // ※
System.out.println(a21.compareTo(a22));
/**/
}
}
class Test2 {
public static void main(String[] arg){
C1 c11 = new C1(1);
C1 c12 = new C1(2);
C2 c21 = new C2(3);
C2 c22 = new C2(4);
System.out.println(c11.compareTo(c12));
System.out.println(c21.compareTo(c22));
}
}
Java はクラスごとにコンパイルできます。 また、 C も関数ごとにコンパイルできます。 ところが、C++ の template 定義だけは分割コンパイルできません。 C++ ではコンパイル時に、ヘッダファイルとして template の定義を読み込み、 実際にプログラムで使用されている部分で実体化されます。 つまり、型引数毎に別々のクラスや関数が生成されます。 また、C++ には演算子のオーバーロード機能がありますので、大小比較も使用 するクラスで再定義できます。 そのため、上記のような Generics の変数の指すオブジェクトを比較する場合、 C++ では実体化の際にどのような定義されているかをチェックすることになり ます。 そのため、型引数に大小比較可能か否かの情報を修飾しなくても問題ありませ ん。
以下は例11-4 の C++ 版です。
以上の点に注目してください。
template <typename E>
class A {
private:
E data;
public:
A(const E& d):data(d){}
bool operator<(const A<E>& x) const {
return data < x.data;
}
};
#ifndef C1DEFINED
#define C1DEFINED
class C1 {
private:
int value;
public:
C1(const int n);
virtual ~C1();
virtual bool operator<(const C1& obj) const ;
};
#endif
#include "C1.hpp"
class C2 : public C1 {
public:
C2(const int n);
};
#include "C1.hpp"
C1::C1(const int n):value(n){}
C1::~C1(){}
bool C1::operator<(const C1& obj) const {
return value < obj.value;
}
#include "C1.hpp"
#include "C2.hpp"
C2::C2(const int n):C1(n){}
#include <iostream>
#include "A.hpp"
#include "C1.hpp"
#include "C2.hpp"
int main(void){
const C1 c11(2),c12(4);
const A<C1> a11(c11),a12(c12);
std::cout << (a11<a12) << std::endl;
const C2 c21(3),c22(5);
const A<C2> a21(c21),a22(c22);
std::cout << (a21<a22) << std::endl;
return 0;
}
CXX=g++
target=rei11-3
$(target): main.o C1.o C2.o
$(CXX) -o$(target) $^
main.o: A.hpp
main.o: C1.hpp
main.o: C2.hpp
C1.o: C1.hpp
C2.o: C1.hpp
C2.o: C2.hpp
さて、このようにして作った木から値を取り出します。 前述していたように帰納的な定義をすると単純になります。
import java.util.*;
class Ki<E extends Comparable<? super E>> {
...
public List<E> toList(){
if(root == null){
return null;
}
List<E> list = new LinkedList<E>();
root.toList(list);
return list;
}
}
class Choten<E extends Comparable<? super E>> {
...
void toList(List<E> list){
if(left != null){
left.toList(list);
}
list.add(data);
if(right != null){
right.toList(list);
}
}
}
通常の配列は整数値を指定することにより、データの読み書きを行います。 連想配列は整数値では無く、任意の型のキーを使いデータの読み 書きを行います。 Java では java.util.HashMap と java.util.TreeMap がそれにあたります。
int[] a1 = new int[3];
a1[1]=5;
a1[2]=a1[1];
java.util.HashMap<String,String> a2
= new java.util.HashMap<String,String>();
a2.put("one","five");
a2.put("two",a2.get("one"));
java.util.HashMap はハッシュ値を利用した検索を使って実現しています。 一方、 java.util.TreeMap は赤黒木という効率の良い順序木を使 用して構成されています。 java.util.HashMap は値を順番に取り出すことはできませんが、 java.util.TreeMap は順序木ですので、値を順番に取り出すことができます。
ここでは前に例で示した順序木の実装に対して、連想配列として活用できるよ うに put と get を実装した例を示します。
まず、頂点のメンバ変数として、key と value を用意します。
class Choten<E extends Comparable<? super E>,F> {
Choten<E,F> left,right;
E key;
F value;
public Choten(E key, F value){
this.key = key;
this.value = value;
}
}
class Ki<E extends Comparable<? super E>,F> {
Choten<E,F> root;
public Ki(){
}
}
次に put を実装します。 要素を検索していき、見つかったらその要素を上書きします。 要素が見つからない場合は、新しく頂点を付け加えます。
class Choten<E extends Comparable<? super E>,F> {
...
public void put(E key, F value){
if(this.key.compareTo(key)==0){
this.value = value;
return;
}
if(this.key.compareTo(key)<0){
if(left == null){
left = new Choten<E,F>(key,value);
return;
}
left.put(key,value);
}else{
if(right == null){
right = new Choten<E,F>(key,value);
return;
}
right.put(key,value);
}
}
}
class Ki<E extends Comparable<? super E>,F> {
...
public void put(E key, F value){
if(root == null){
root = new Choten<E,F>(key,value);
return;
}
root.put(key,value);
}
}
同様に get も実装します。 get では見つからない場合は null を返します。
class Choten<E extends Comparable<? super E>,F> {
...
public F get(E key){
if(this.key.compareTo(key)==0){
return value;
}
if(this.key.compareTo(key)<0){
if(left == null){
return null;
}
return left.get(key);
}else{
if(right == null){
return null;
}
return right.get(key);
}
}
}
class Ki<E extends Comparable<? super E>,F> {
...
public F get(E key){
if(root == null){
return null;
}
return root.get(key);
}
}
すると次のようなテストプログラムが動作します。
class Test {
public static void main(String[] arg){
Ki<String,Integer> tree = new Ki<String,Integer>();
tree.put("07ec999",80);
tree.put("07ec990",90);
tree.put("07ec994",60);
tree.put("07ec992",50);
System.out.println(tree.get("07ec990"));
}
}
順序木は中央の頂点の値は左側のどの頂点の値よりも大きく、右側のどの頂点 の値よりも小さいです。 従って、順序木が出来上がった時、木の構造を縦に自然に潰すと、値の小さい 頂点から大きい頂点まで整列することがわかります。
そこで、与えられた配列に対して、順序木に格納しているように値を振り分け ることで、配列の中身を整列できます。 つまり、次のような手順になります。
まず、配列の中で中央の頂点に入れる値を勝手に 0 番目の値と決めてしまい ましょう。 次に分類ですが、配列の左と右の両方から見て行き、中央の頂点より大きい値 を左から探し、中央の頂点より小さい値を右から探すようにします。 そして、両方とも見つかったら交換します。 このようにすると最終的に左側に小さい値、右側に大きい値が得られます。 そして、左と右に再帰的に同じ処理をすれば全ての値が整列できます。 このような整列法を クイックソートと言います。 この整列法は現在知られている整列法のうち、実際に実装して使用する上ではもっ とも速い整列法として知られています。
import java.util.*;
public class QSort {
public static <E extends Comparable<? super E>>
void sort(E[] array){
partition(array,0,array.length-1);
}
private static <E extends Comparable<? super E>>
void partition(E[] array, int from, int to){
if(from>=to) return;
int f = from+1;
int t = to;
E s = array[from];
while(f!=t){
while(array[f].compareTo(s)<=0 && f<t) f++;
while(array[t].compareTo(s)>0 && f<t) t--;
E tmp = array[f];
array[f] = array[t];
array[t] = tmp;
}
f--;
E tmp = array[from];
array[from] = array[f];
array[f] = tmp;
partition(array,from,f);
partition(array,t,to);
}
public static void main(String[] arg){
Integer[] a = {3,6,8,2,1,9,2,5,5};
System.out.println(Arrays.toString(a));
QSort.sort(a);
System.out.println(Arrays.toString(a));
String[] b = {"windows","macintosh","unix"};
System.out.println(Arrays.toString(b));
QSort.sort(b);
System.out.println(Arrays.toString(b));
}
}
値 1, 2, 3, 4 を持つ順序木を全て書きだしなさい。
全ての二分木の形に対して、それぞれに格納の方法が一通りだけ可能です。
連想配列 Ki<E> において、 java.util.TreeSet<E> 型の key の集合を返すメソッ ド Set<E> keySet() を実装し、例11-7 において連想配列に入っている 内容を学籍番号順に並べて出力するプログラムを書きなさい。
配列をクイックソートするプログラムを書きなさい。