第 14 回 ソート
本日の内容
このドキュメントは
http://edu.net.c.dendai.ac.jp/
上で公開されています。
順番にデータを並び替えることをソートと言います。
今回はソートのアルゴリズムを紹介します。
始めに前回示した順序木によるソートの分析をし、そのあと、配列変数に対す
るソートのアルゴリズムを示します。
計算量
プログラムの効率を比べるにはどうしたら良いでしょうか?
単純に思いつく方法は適当なテストデータを作り、そのデータを処理する時間
を計ることです。
しかし、この方法は実行するコンピュータにより差が出ますし、同じコンピュー
タでも毎回時間が異なることがあります。
また、この方法に対して最も高速なプログラムは、入力がテストデータかどう
か判断して、テストデータが入力された時はあらかじめ計算しておいた値を出
力するものです。
しかしこのようなプログラムが最も効率的と言えるでしょうか?
結局、プログラムが効率的かどうかを調べるのに、特定の状況下でプログラム
の動作時間を計るのはあまり意味のあることではありません。
しかし、世間では特定のプログラムを実行させて、実行時間を計ることでコン
ピュータの性能を調べるベンチマークテストなども行われており、この特定条
件下の実行時間計測が指標として使われることがしばしばあります。
ところがそれに対して、実際にあった話ですが、あるグラフィックボードはベ
ンチマークテストだとわかると複雑な処理を止めて、いい加減な出力を素早く
出すようにしていたことがバレタことがあります。
実際、ベンチマークテストではライバル社の同等品より良い数値が出てました
が、実際使用すると性能が劣っていたということがありました。
そこでいろいろな数学的な考察から、以下のようにプログラムを評価すると効
率が比較できることがわかっています。
まず、プログラムに対して、入力の長さを n とした時に実行するステップ数
を n の関数の形で計算します。
そして、関数が複数の項の足し算になっている時、もっとも増え方が速い項を
取り出し、係数を除いたものを考えます。
このような項を取り出すことをオーダーを求めると言います。
そして、この入力の長さ n に関する実行時間を表す関数のオーダがプログラ
ムの効率の指標として考えられています。
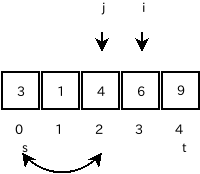
例えば、次のプログラムの効率を評価します。
#include <stdio.h>
int main(void){
int i,j,s;
scanf_s("%d",&i);
s=0;
for(j=1;j<=i;j++){
s+=j;
}
printf("%d\n",s);
}
- main, int などの手間はとりあえず 1 ずつとします。
- scanf_s では、入力される長さ(文字数)程度の手間が必要なので n とします。
ここで、 i と n の関係は i ≦ 10 n≦ 24 n または
log i ≦ n となること
に注意して下さい(i は高々 n 桁で表現できる数)。
- s=0 の手間は 1 とします。
- for のカッコの中の手間は j=1 が 1 、 j<i は i の桁数程度の手間
になるので n 、 j++ も最大値は i 位なので n とします。
但し、繰り返し回数は i 回 ≦ 24 n回です。
- s+=j の手間ですが、 s の最大値は大体 i2 なので、その桁
数は log i2 = 2 log i = 2 n とします。これを 24 n
回繰り返します。
- printf の手間は s の桁数程度なので、 2 n とします。
すると全部の手間は 1+1+n+1+(1+24 n(n+2n+n))+2n
= 24 n・4n + 3n + 3 となります。
この中でもっとも増え方の速い項は
24 n・4n です。そして、係数を取り除くと 2n・n と
なります。
この時、このプログラムの実行時間はオーダー2n・n
だと言います。
式で書くと O(2n・n)となります。
プログラムの計算時間の評価はこのように関数の形で行います。
どうしてこのように雑な関数の取り扱いになるかは
1部データ構造とアルゴリズム第6回アルゴ
リズムに関する数学 3. 計算量を参照して下さい(但し Internet Explorer
ver.6 のような MathML に対応していないブラウザでは見られません)。
順序木の計算量
前回示した順序木の処理の計算量を求めます。
深さ k の木にはおおよそ 2k個のデータを詰め込めます。従って、
データ数が n 個の順序木の深さはおおよそ log n になります。
add 関数は新しく頂点を付け加える作業をします。
そのためには木の端まで木をたどり、そこに頂点を新しくつくって接続します。
木の端までたどるには木の深さ程度の手間 O(log n) 程度かかります。
新しく頂点を作る作業はO(1)程度かかるとします。
従って、add 関数一回の手間は O(log n)です。
これをデータ数 n だけ繰り返す必要があるので
与えられたデータから順序木を作るには O( n log n ) の手間がかかります。
一方 show 関数は全データを表示するだけですから O(n) の手間がかかります。
従って順序木を使用した並べ替えにかかる手間は O(n log n + n ) = O(n log
n) となります。
効率の悪い並び替え
これから示すのは良く知られている効率のわるい並び替えアルゴリズムです。
これらをレポートに使用してはいけません。
なおこれからは配列変数に対してソートを行うことを考えます。
バブルソート
大きいものと小さいものが順にならんでいたら、場所を入れ換えることを繰り
返すと、いつかはすべてが小さいもの順に並びます。
配列変数に対して、配列の添字の小さい順に値を見ていき、大きいものの後に
小さいものが来たら場所を入れ換えることを繰り返します。
すると、配列の最後まで行った際、配列の最後には必ずもっとも大きな値が来
ます。
そこで、もう一度添字の小さい順にこの入れ換え作業を行うと、二番目に
大きな値が配列の後ろから二番目の位置に来ます。
従って、配列の長さに対応した回数だけこの添字の小さい順に並べ変え作業を
行うと、配列の要素すべてが順番に並ぶことになります。
これをプログラムにすると次のようになります。
#include <stdio.h>
void disparray(int *p){
while(*p!=-1){
printf("%d ",*p++);
}
printf("\n");
}
int main(void){
int a[]={4,5,3,2,1,-1};
int i,j,temp;
disparray(a);
if(a[0]!=-1){
for(i=0;a[i]!=-1;i++){
for(j=1;a[j]!=-1;j++){
if(a[j-1]>a[j]){
temp=a[j-1];
a[j-1]=a[j];
a[j]=temp;
}
}
}
}
disparray(a);
}
配列の長さを n とすると、二重ループのそれぞれが n 回回るので、
O(n2)の効率になります。
挿入法
ソートされた配列に対して、一つ値を適切な位置に挿入することを繰り返して
ソートされた列を増やしていく方法を挿入法と言います。
挿入される位置を探すのに二分探索法を使うと多少は効率的ですが、配列変数
の途中に値を挿入するのに、配列の長さに比例した部分を動かす必要があるた
め、結局挿入する手間が O(n) で、挿入する値が n 個となるので
O(n2) になります。
#include <stdio.h>
void disparray(int *p){
while(*p!=-1){
printf("%d ",*p++);
}
printf("\n");
}
void insert(int val, int *from, int *to){
int *p,*q;
for(p=from; p!=to; p++){
if(*p > val){break;}
}
for(q=to;q>p;q--){
*q=*(q-1);
}
*p=val;
}
int main(void){
int a[]={4,5,3,2,1,-1};
int i,j,temp;
disparray(a);
if(a[0]!=-1){
for(i=1;a[i]!=-1;i++){
insert(a[i],&a[0],&a[i]);
}
}
disparray(a);
}
クイックソート
配列に対して、順序木を使ったソートに匹敵する効率でソートするにはどうす
ればいいでしょうか?
そのためには、順序木にデータを入れるようにデータを動かす必要があります。
順序木の性質により根の頂点に入るデータに対して、左に接続する木に含まれ
るデータは全て値が小さく、右に接続する木に含まれるデータは全て値が大き
くなります。
そこで、配列に対して、根に入る値、左側に入る値、右側に入る値を分類する
ことを考えます。
この作業を行う関数を partition と呼ぶことにします。
すると、左側に入る値に対しても partition 、右側に入る値に対しても
partition を行うことにより最終的に全てのデータを順序木のどこに配置すれ
ば良いかを決めることができます。
配列の中身をソートするには、左側に入る値を前に、右側に入る値を後ろに移
動させる必要があります。
そして、左側に入る値を前半部分、右側に入る値を後半部分に移動させられれ
ば、こんどはその部分に対して partition を実行させます。
従って、 partition の引数にはどこからどこまでを対象にするかを与える必
要がありますので、関数宣言は次のようになります。
void partition(int s, int t);
そして、内部では次のようにします。
- 配列の名前を a とします。
- s>=t ならば何もせずに終了します。
- a[s] を勝手に根に入る値と定めてしまいます。
- 検索する領域を示す変数を i=s+1, j=t とします。
- 以下を繰りかえします
- a[s]<a[i]となる a[i] を i を増やしながら探します。但し、範囲外に出な
いように注意します。 i は最大で t+1 になります。
- a[s]>= a[j]となるa[j] を j を減らしながら探します。但し、範囲外に出な
いように注意します。 j は最小で s になります。
- もし i< j でないなら、繰り返しを止めます
- a[i] と a[j] を交換します。
- a[s] を a[j] と交換します。
これにより a[j] 以下の要素が a[s] から a[j-1] まで、
a[j] より大きい要素が a[j+1] より a[t] まで並ぶことになります。
- partition(s,j-1) と partition(j+1,t) を実行します。
このようにすると平均で O( n log n ) でデータをソートできます。
このようなソートをクイックソートと言います。
実行例
-
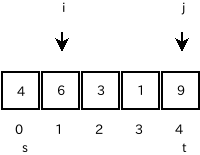
配列 a[]={4,6,3,1,9} に対して partition 関数が呼ばれたとします。
引数は s=0, t=4 です。
すると、先頭の a[s] を基準値として、この配列を二分割(先頭を別に考
えると三分割)するようにデータを交換します。
まず、s の隣 s+1 を i とし、 t を j とします。
そして、i を順々に増やしていき、 a[s]より大きい要素を探します。
また、 j を順々に減らしていき、a[s]以下の要素を探します。
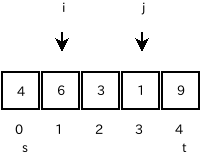
-
i=s+1, j=t-1 でそれぞれ、 a[i]=6 > a[s]=4 >= a[j]=1 が見つかりました。
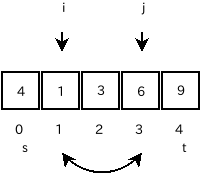
-
a[i]とa[j]を交換します。
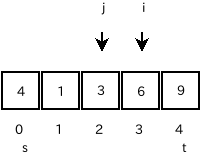
-
再び検索すると、 a[i]=6 > a[s]=4 >= a[j]=3 が見つかりますが、
i=3 < j=2 ではないので、これで検索は終了です。
-
左側の要素の右端a[j]と、a[s]を交換します。
そして、左側 a[s]からa[j-1] と右側 a[j+1]からa[t]で paritition を呼
び出します。
演習14-1
- クイックソートのプログラムを作りなさい。
- 作成したプログラムに対して、下の値を与え、ソートした結果を出力させ
なさい。
#define N 11
int a[N]={4,6,3,1,9,7,5,0,2,6,8};
演習14-2
大きい順にソートするプログラムを書き、上記のデータをソートし出力させな
さい。
坂本直志 <sakamoto@c.dendai.ac.jp>
東京電機大学工学部情報通信工学科