図1
このドキュメントは http://edu.net.c.dendai.ac.jp/ 上で公開されています。
文字の処理を行うには基本的には次のようにして、一文字ずつ処理をします。
/* x が文字の配列の時 */
for(i=0;x[i]!='\0';i++){
/* x[i] (x の i 番目の文字)の処理 */
}
文字自体はコンピュータ内部では数値として処理されます。 文字に振られている数値を文字コードと呼びます。 文字定数 'x' は文字 x を表す文字コードを表しています。 文字の操作も数値と同様ですので、加減乗除ができます。 通常の文字コードでは文字の順番通りに文字コードが振られています。 従って、 'a' から 'x' までの間隔と 'A' から 'X' までの間隔は等しいです。 つまり、 'x'-'a'='X'-'A' となるので、 'X'='x'-'a'+'A' が成り立ちます。 これは大文字小文字変換を行うための式になります。 一方、文字コード 'x' は 'a' 以上 'z' 以下です。つまり、 ('x'>='a')&&('x'<='z') が成り立ちます。 これは 'x' に限らず英小文字なら成り立ちます。つまりこの条件式は英小文 字かどうかを判定できる論理式になります。 以上により、文字配列中の英小文字を大文字に変換するプログラムは以下のよ うになります。
#include <stdio.h>
main(){
char x[]="This is a pin.";
int i;
for(i=0;x[i]!='\0';i++){
if((x[i]>='a')&&(x[i]<='z')){
printf("%c", x[i]-'a'+'A');
}else{
printf("%c", x[i]);
}
}
printf("\n");
}
#include <stdio.h>
main(){
char x[]="abc";
char y[]="def";
char z[50];
/* 文字列をつなげる処理 */
printf("文字列 %s と %s をつなげると %s になる\n",x,y,z);
}
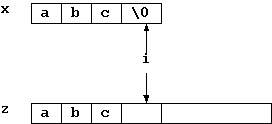
C 言語には文字列型という変数はありません。 従って、「文字列型変数へ文字列を代入」という操作はできません。 あるのは、文字型だけなので、一文字一文字コピーしていくしかありません。 まず、問題を簡単にするために、文字配列 z[] に x[] をコピーしていくこと を考えましょう。 これは、 x[0] を z[0] に、 x[1] を z[1] にと、文字列が終るまで('\0' が見 つかるまで)繰り返せば良いので、次のように書けます。
int i;
for(i=0;x[i]!='\0';i++){
z[i]=x[i];
}
但しこの手法だと、 '\0' を検出するとコピーを止めますので(図1)、 '\0' 自体はコピーされません。 従って、z[] の最後の文字は '\0' で終ってません。 但し、コピーが終った後、 x[i] は '\0' を示しています。そして z[i] は x[i] をコピーし終った直後を示してます。 そこで、z[i] に y[0] を、z[i+1] に y[1] をと y[] が終るまでコピーすれ ば、これで x[] と y[] をつなげることになります(図2)。 別の変数 j を用意すれば、z[i+j] に y[j] をコピーすれば良いので、次のよ うに書けます(j は宣言済みとします)。
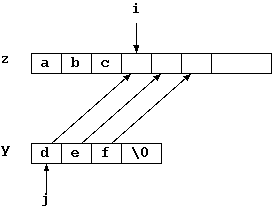
for(j=0;y[j]!='\0';j++){
z[i+j]=y[j];
}
そして、z[] の最後に '\0' を入れます。 これらをまとめると、文字列の結合ができます。
#include <stdio.h>
main(){
char x[]="abc";
char y[]="def";
char z[50];
int i,j;
for(i=0;x[i]!='\0';i++){
z[i]=x[i];
}
for(j=0;y[j]!='\0';j++){
z[i+j]=y[j];
}
z[i+j]='\0';
printf("文字列 %s と %s をつなげると %s になる\n",x,y,z);
}
なお、 z[i+j] の代わりに z[i] とし、 j と一緒に i を増やしていっても良 い。
C 言語では全ての文や式に値を持ちます。 例えば代入文は代入した数を値に持ちます。 j=0 という代入文の値は 0 です。 従って次のような記法が可能です(代入文は右から処理されます)。
i=j=0
この場合、「j=0」 により j に 0 が代入されますが、「j=0」の式の値は 0 なので、 i にはこの式の値 0 が代入されます。
条件文の式の値は、真であれば 1、偽であれば 0 です。従って、 0==0 は 1、1==0 は 0 の値を持ちます。一方、条件文では、 0 なら偽、0 以 外の値なら真だと判定します。したがって、次の文は同じ意味を持ちます。
if(x!=0){}
if(x){}
従来は標準入出力(Standard I/O)をやってましたが、 Microsoft Visual Studio .NET での取り扱うには特別な操作が必要です。 ここではファイル名を指定する形のファイルの入出力を取り上げます。
いままでは文字を画面に出力していましたが、ここでは画面と同じようなイメー ジでファイルを作成することを考えます。
ファイルに出力するには fprintf という関数があり、使用方法はほぼ printf と同様です。 但し、ファイルを扱うには識別子(ファイルハンドル)が必要です。 これは fopen 関数でファイル名を指定して取得します。 では、ここでファイルを扱う手順を説明します。
以下はファイル hello.txt に Hello World! を書き込むプログラムです。
#include <stdio.h>
main(){
FILE *fh;
if((fh=fopen("hello.txt","w"))==NULL){
fprintf(stderr,"ファイルを作成できませんでした\n");
return 1;
}
fprintf(fh,"Hello World.\n");
fclose(fh);
}
配列と異なり、ファイルはコンピュータのディスクの状態により、処理が可能 になったり不能になったりします。 そのため、エラーが起きたときの処理を考えなければなりません。 例えばファイルの場合、書き込みたいファイル名を既にフォルダが使っているとき、 オープンしようとすると失敗します。
このような場合、失敗したことを検知し、エラーを表示して止める必要があり ます。 エラーを検知してエラー処理するような if 文を ガード文と言い ます。 ファイルのオープンの失敗に関しては次のようなガード文になります。
fh=fopen("ファイル名","w");
if(fh==NULL){
エラー表示
プログラムの停止
}
正常な処理
...
あるいは
if((fh=fopen("ファイル名","w"))==NULL){
エラー表示
プログラムの停止
}
正常な処理
...
まず、エラーを表示するには、エラー専用の出力先があります。 システムが用意している標準エラー出力と呼ばれるファイルハンドルは stderr となります。 これを用いると、エラー表示は次のようになります。
fprintf(stderr,"ファイルを開けません\n");
なお、stderr の他に、 stdin は標準入力、 stdout は標準出力といい、それぞれキーボード、 画面に割り当てられています。 stdin, stdout, stderr はオープン、クローズの必要はありません。
プログラムは最後の行を終えると自動的に停止しますが、プログラムの途中で 停止させたい場合、exit 関数または return 文を使 用します。 ここでは return 文を使用することを考えます。 return に関する詳しい説明は関数の章で説明します。 ここでは、正常終了なら return 0 、異常終了なら return (0以外の値) を使 用するということだけを覚えておきます。
以上をまとめると、ファイルを開くときのエラー処理は次のように書けます。
if((fh=fopen("ファイル名","w"))==NULL){
fprintf(stderr,"ファイルを開けません\n");
return 1;
}
正常な処理
...
C 言語でファイルから一文字得るには getc() 関数を使います。 この関数を使用すると、入力された文字が文字型の値として得ることができま す。 つまり c=getc(ファイルハンドル); とすると、一文字得ることができます。 一方、ファイルの終りに達すると EOF という値になります。
なお、 EOF は '\0' と違い、文字ではありません。 したがって、 c を文字型で定義すると誤動作します。 getc の出力を受けとるには必ず int で宣言する必要があります。
さて、ファイルの終りまで一文字ずつ読みながら処理をするには、一文字読む 毎にEOF かどうか判定する必要があります。 つまり、プログラムは「(A)一文字読み、読んだ文字が EOF でないとき→(B) 読んだ文字を処理をする」ということ繰り返すことになります。 つまり概念的には次のようなプログラムになります。
while(一文字読み、読み込んだ文字が EOF でないとき){
読んだ文字を処理する
}
while 文の条件は式の値を利用すると次のように書けます。
while((c=getc(fh))!=EOF){
読み込んだ文字の入っている変数 c に対する処理
}
次はファイル a.txt をファイル b.txt にコピーするプログラムです。
#include <stdio.h>
main(){
FILE *fa, *fb;
int c;
char fileA[]="a.txt";
char fileB[]="b.txt";
if((fa=fopen(fileA,"r"))==NULL){
fprintf(stderr,"ファイル %s を開けませんでした",fileA);
return 1;
}
if((fb=fopen(fileB,"w"))==NULL){
fclose(fa);
fprintf(stderr,"ファイル %s を開けませんでした",fileB);
return 1;
}
while((c=getc(fa))!=EOF){
fprintf(fb,"%c",c);
}
fclose(fb);
fclose(fa);
}
次の操作で変数 i,j の値はどうなっているか?
次のプログラムを完成させ、ファイルの文字数を数えるようにしなさい。 また、このプログラムが何文字あるか、このプログラムそのものを入力ファイ ルとして与えて調べなさい。
#include <stdio.h>
main(){
FILE *fh;
char filename[]="file.txt";
int c;
int n=0;
if((fh=fopen(filename,"r"))==NULL){
fprintf(stderr,"ファイル %s を開けませんでした\n",filename);
return 1;
}
while((c=getc(fh))!=EOF){
/* 一文字受けとったら、 n を一増やす */
}
printf("合計 %d 文字\n",n);
fclose(fh);
}
変数 x に文字を与えておき、その文字がファイル中に何文字現れたかを数え るプログラムを書きなさい。
ファイルの中の行が何行あるかを数えるプログラムを書きなさい。
ファイルの中の各行がそれぞれ何文字あるかを出力するプログラムを書き なさい。
入力ファイルに対して、一行が長い場合、 10 文字ずつ折り返すプログラムを 作りなさい。
以下の図形を zukei.txt というファイルに書き込みなさい。 但し、辺の長さ 3 は #define で N に定義されている値とし、 N の値を変え ると辺の長さが変わるようにしなさい。
〇 〇 〇 〇 〇 〇 〇 〇
きちんとした図形が描けるまではファイルに書かず stdout に書くようにする とデバッグが楽になります。 つまり、次のようにします。
/* if((fh=fopen(filename,"w"))!=NULL){ */
if(1){ fh=stdout;
MS-DOS プロンプトやコマンドプロンプトでは、キーボードを押すと字が入力 され、画面に字が表示されます。 しかし、このキーボードや画面の関係を変えることが可能です。 例えば、プログラムの実行結果をファイルに残したり、プログラムにキーボー ドからではなくファイルの内容を入力したりできます。 コンピュータの入出力は基本的にはキーボードと画面が対応していますが、特 定のファイルに変更が可能になっています(この入出力の変更のことをリ ダイレクトと言います)。
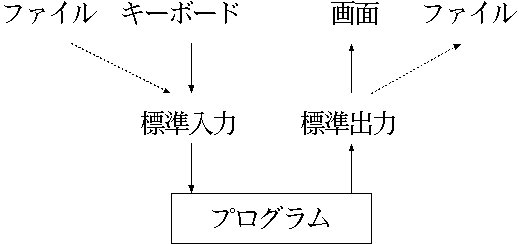
標準出力を変更するにはコマンドを入力した後、「> 出力ファイル名」 を付け足します。 例えば、ディレクトリの内容をファイルに保存するには次のようにします。
dir > file1
このようにするとディレクトリの内容は画面に表示されず、 file1 に保存さ
れます。
echo abc > file2
標準入力を変更するにはコマンドを入力した後、「< 入力ファイル名」を つけます。 例を説明する前に、次のファイルを作って下さい。ファイル名は file3 にして下さい。
3 1 2
このファイルを sort コマンドに入力するには次のようにします。
sort < file3すると、画面に与えた数が小さい順に出力されます。
sort コマンドはファイルの内容を小さい順に並べるコマンドです。 ファイルの最後に一番小さい値が来たら、その値を先頭に表示する必要がある ため、 sort の処理はファイルを全て読み終えてからでないと実行できません。 sort に限らず、ファイルを処理するプログラムはファイルの終りを知る必要 があります。 そのため、 OS はファイルが終ると EOF記号(End of File)という特殊な記号 (番兵)をプログラムに与えます。これにより、プログラムは ファイルが終ったことを知ることができます。 MS-DOS や Windows では Ctrl-Z という記号になります。 例えば、次のようにすると、 sort コマンドはキーボードから入力した数字を 並べ替えます。
例 sort[Enter] 3[Enter] 1[Enter] 2[Enter] [Ctrl-Z][Enter]
コマンドの出力をファイルに「追加」したい時は >> を使用 します。
例 echo abc > file1 echo def >> file1
コマンドの出力を、他のコマンドの入力にしたい時は |(縦棒) を使用しま す。このように複数のコマンドをつなげて処理することをパイプ処理 と言います。
例 dir | sort dir | more dir | sort | more
Visual Studio .NET で標準入出力のリダイレクトを使うには以下のようにし ます。